
Tabata, Tomoji, University of Osaka, Japan, tabata@lang.osaka-u.ac.jp
Outline of this study
This paper describes a new approach to Dickens’ style, applying a state-of-art machine-learning classification technique in an effort to distinguish Dickens’ texts from a reference corpus of texts. This study makes use of Breiman’s (2001) ‘Random Forests’ in order to spotlight lexical items Dickens consistently used or avoided in his texts in comparison with the control set.
By demonstrating how we can identify Dickensian stylistic markers, this study also proposes Random Forests as a more powerful alternative for traditional ‘key word’ analysis, a popular method in corpus linguistics for extracting a set of words that characterize a particular text, a particular register/(sub)corpus, or a particular diachronic set of texts, etc. from others.
In a typical key word analysis, the significance of difference between two sets of texts in the frequency of a word is calculated based on log-likelihood ratio (LLR, henceforward; Tun- ning 1993; Rayson & Garside 2000). However, LLR alone provides little information about proportion of difference between the sets, not to mention whether or not a particular word is distributed evenly throughout each set of texts. LLR tells us only about the ‘significance’ (NOT the ‘degree’ of) of discrepancy between two sets of texts with respect to frequency of a partic- ular lexical variable. Thus, a potential drawback of the method is seen in a case where a word occurring with exceptionally high frequency in a single text can over-represent the entire set it belongs to. Using Random Forests, this study will address such an issue and provide means to identify a more reliable set of markers of Dickens’ style.
The drawbacks of traditional ‘key’ word analysis
Textual analysis often begins with identifying key words of a text on the assumption that key words reflect what the text is really about and that they are likely to reflect stylistic features of the text as well. Key words as a corpus linguistic terminology are defined as words that ‘appear in a text or a part of a text with a frequency greater than chance occurrence alone would suggest’ (Henry & Roseberry 2001: 110). A popular method to measure ‘keyness’ is to calculate an LLR to assess the significance of difference between the expected frequency and the observed frequency of a word in a text. However, one drawback of this approach emerges when we compare Dickens’ texts with, for example, a set of texts by his contemporary Wilkie Collins.
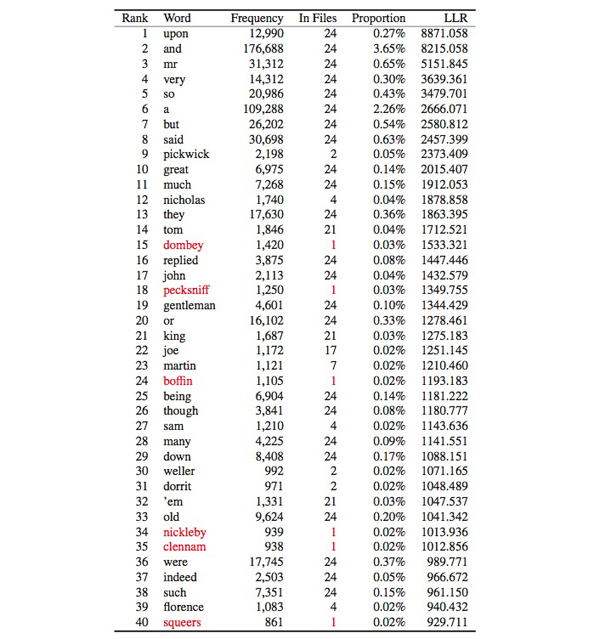
Table 1: 40 most significant key words of Dickens compared with Wilkie Collins (sorted according to log-likelihood ratio (LLR))
Although proper names such as Dombey, Pecksniff, and Boffin are ranked among the top 40 Dickensian ‘key’ words, none of these would normally be counted as important at least from a stylistic perspective, apart from the fact these represent a few peculiar Dickensian characters, who appear only in a single text. As we go down the list, it turns out that 19 out of the top 100 are those which occur only in a single text. As we turn our eyes to words listed as Collins’s key words, we see 35 out of the top 100 are from a single text. If we include words that occur only in a very small number of texts, the proportion becomes even greater.
Another (though less obvious) drawback comes from the mathematical fact that LLR em- phasizes high-frequency items: in fact, high-frequency words tend to predominate towards the top of the list in Table 1, with words in lower frequency-strata not tending to be highlighted easily. A better alternative is needed.
Random Forests as a stylometric tool
Random Forests (henceforth, RF) are a very efficient classification algorithm based on ensemble learning from a large number of classification trees (thus ‘forests’) randomly generated from the dataset. As RF builds a classification tree from a set of bootstrap samples, about one-third of the cases are left out for running an internal unbiased estimate of the classification error each time. The process is iterated until n-th (500th by default) tree is added to the forests, there being no need for cross-validation or a separate test (Breiman and Cutler, ND). One of the most prominent features of RF is its high accuracy in respect to classification of data sets. In the experiments reported by Jin and Murakami (2007), RF was unexcelled in accuracy among other high-performance classifiers, such as k Nearest Neighbor, Support Vector Machine, Learning Vector Quantification, Bagging and AdaBoosting, in distinguishing between 200 pieces of texts written by 10 modern Japanese novelists. In my own experiments, RF constantly achieved accuracy rates as high as 96–100% in distinguishing Dickens’s texts from the control set of texts.
RF is capable of handling thousands of input variables and of running efficiently on large database.1 The first series of experiments with RF in this study were on a set of 24 Dickens’s texts versus a comparable set of 24 Wilkie Collins’ texts with from more than five thousand to as few as fifty word-variables. The results were fairly consistent with over 96% accuracy. The best of the results was seen when 300 input variables are used (Table 2). The out-of-bag (OOB) estimate of error rate was 0%, or 100% accuracy in distinguishing between Dickens’s and Collins’s texts.
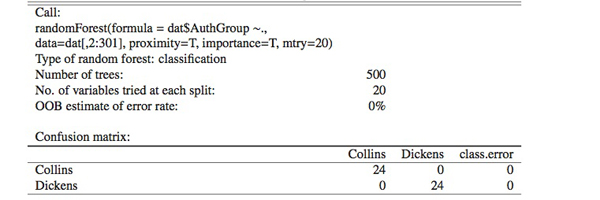
Table 2: A result of running Random Forests

Figure 1: A multi-dimensional scaling diagram based on the proximity matrix generated by RF: Dickens versus Collins
RF computes proximities between pairs of cases that can be visualized in a multidimensional scaling diagram as in Figure 1. Dickens’s texts and Collins’s texts, respectively, form distinct clusters, with two unusual pieces by Collins shown as outliers: Antonina (1850), which has its setting in ancient Rome, and the travel book Rambles beyond Railways (1851).
Of further merit is the ability to highlight the lexical items that contribute most strongly to authorial classifications. RF shows the importance of variables in two measures: Mean-DecreaseAccuracy and MeanDecreaseGini. The former indicates the mean of decrease in the accuracy of classification when a particular variable is excluded from analysis. The latter shows the mean of decrease in Gini index, an index of uneven distribution of a particular variable between the groups, when the variable in question is excluded from analysis. The two indices are comparable to each other. Table 3 list marker words of Dickens and Collins, respectively, in the order of importance (sorted according to the mean decrease in Gini index).

Table 3: Import variables: Dickens markers and Collins markers (in the order of importance)
A close comparison of Table 3 with Table 1 will show how RF helps identify words with high discriminatory power. Proper nouns and words distributed unevenly in each set now have effectively made way for words which are consistently more frequent in one author than the other. Although Table 3 in itself is worth scrutiny in that it reveals how Dickens markers are contrasted with Collins markers, it is necessary to compare Dickens texts with a larger and more representative corpus of writings in order to spotlight Dickens’s stylistic features in a wider perspective.
Comparing and contrasting Dickens with a reference corpus of 18th-and 19th-Century authors
In the following analysis, the set of 24 Dickens’ texts was compared with a reference corpus consisting of 24 eighteenth-century texts and 31 nineteenth-century texts.
When 300 input variables were used, the OOB estimate of error rate fell down to 1.28%, or 98.72% of runs correctly distinguishing Dickens from the reference set of texts. Fig. 2 distinguishes between the Dickens cluster and the control cluster. One seeming anomaly is the position of A Child’s History of England (1851), which finds itself as an outlier. This history book for children is considerably different in style from other Dickensian works. Therefore, it is not unexpected for this piece to be found least Dickensian, a phenomenon in consistent with previous multivariate studies based on other linguistic variables, such as collocates of gentleman (Tabata 2009: 272), –ly adverbs (Tabata 2005: 231) and part-of-speech distribution (Tabata 2002: 173).

Figure 2: A multi-dimensional scaling diagram based on the proximity matrix generated by RF: Dickens versus reference corpus

Table 4: Important variables: Dickens versus the reference corpus (in order of importance)
Table 4 arrays major Dickens markers. Although relationships among these words are com- plex enough to defy straightforward generalization, one could see the predominance of words related to description of actions – typically bodily actions – or postures of characters rather than words denoting abstract ideas. Words like eyes, hands, saw, looked, back in particular have caught eyes of critics such as Hori (2004) and Mahlberg (2007a, 2007b), which suggests the present methodology is well-grounded. Stubbs (2005) states:
[E]ven if quantification only confirms what we have already know, this is not a bad thing. Indeed , in developing a new method, it is perhaps better not to find anything too new, but to confirm findings from many years of traditional study, since tis gives confidence that the method can be relied on (Stubbs 2005: 6).
In order to determine local textual functions (Mahlberg 2007a, 2007b) each of these words performs, it is of course necessary to go back to texts and examine the words in local contexts with the help of other tools such as concordance, collocation, and n-grams. However, the present method opens up a promising pathway to deeper textual analysis. The results of this study will also point to the effectiveness of this approach in cases of disputed authorship.
Appendix
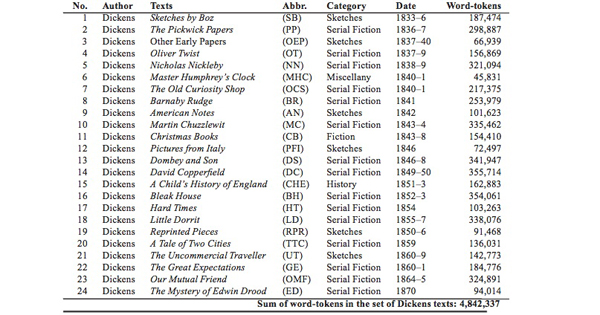
Table 5: Dickens component of ORCHIDS
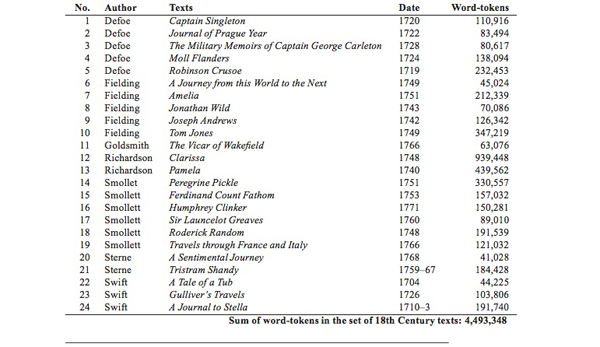
Table 6: 18th Century component of ORCHIDS
Table 7: 19th Century component of ORCHIDS
References
Breiman, L. (2001). Random forests. Machine Learning 45: 5-23.
Dunning, T. (1993). Accurate methods for the statistics of surprise and coincidence. Computational Linguistics 19(1): 61-74.
Henry. A., and R. L. Rooseberry (2001). Using a small corpus to obtain data for teaching genre. In M. Ghadessy, A. Henry and R. L. Roseberry (eds.), Small Corpus and ELT. Amsterdam,Philadelphia, Pa.: John Benjamins, pp. 93-133.
Hori, M. (2004). Investigating Dickens’ Style: A Collocational Analysis. New York: Palgrave Macmillan.
Jin, M., and M. Murakami (2007). Random forest hou ni yoru bunshou no kakite no doutei (Authorship Identification Using Random Forests), Toukei Suuri (Proceedings of the Institute of Statistical Mathematics) 55(2): 255-268.
Mahlberg, M. (2007a). Corpus stylistics: bridging the gap between linguistic and literary studies. In M. Hoey et al. (eds.), Text, discourse and corpora. Theory and analysis. London: Continuum, pp. 217-246.
Mahlberg, M. (2007b). Clusters, key clusters and local textual functions in Dickens. Corpora 2(1): 1-31.
Rayson, P., and R. Garside (2000). Comparing Corpora Using Frequency Profiling. Proceedings of the Workshop on Comparing Corpora, Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), 1-8 October 2000, Hong Kong, 1-6. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/phd/phd2003.pdf.
Stubbs, M. (2005). Conrad in the computer: examples of quantitative stylistic methods. Language and Literature 14(1): 5-24.
Tabata, T. (2002). Investigating Stylistic Variation in Dickens through Correspondence Analysis of Word-Class Distribution. In T. Saito, J. Nakamura and S. Yamasaki (eds.), English Corpus Lin- guistics in Japan. Amsterdam: Rodopi, pp. 165-182.
Tabata, T. (2005). Profiling stylistic variations in Dickens and Smollett through correspondence analy- sis of low frequency words. ACH/ALLC 2005 Conference Abstracts, Humanities Computing and Media Centre, University of Victoria, Canada, pp. 229-232.
Tabata, T. (2009). More about gentleman in Dickens. Digital Humanities 2009 Conference Abstracts, University of Maryland, College Park, June 22–25, 2009, The Association for Literary and Lin- guistic Computing, the Association for Computers and the Humanities, and the Society for Digital Humanities – Société pour l’étude des médias interactifs, pp. 270-275.
Notes
1.Breiman, L., and A. Cutler, Random Forests. Online resource. (Last accessed 20 October 2011.) http://stat- www.berkeley.edu/users/breiman/RandomForests/cc_home.htm