
Schnöpf, Markus, Berlin-Brandenburg Academy of Sciences and Humanities, Germany, schnoepf@bbaw.de
Introduction
In 2007 begun the project Corpus Coranicum located at the Berlin-Brandenburg Academy of Science and Humanities with an estimated duration of twelve years. A goal of the project is a holistic documentation of the holy text. The project consists of different modules: Collection of early manuscripts, documentation of environmental texts to the Quran, documentation of alternate writings and finally a commentary on each sura of the Quran. In the last years the technological infrastructure has been set up and data was collected in a SQL database. The commentary of the was realised in XML and is stored in a XML-database. The website of the project thus combines SQL and XML in an integrated information system. Lately, a bibliography consisting of 8000 references was added to the system. Further investigations are directed more on a scientific dating, analysing the materiality of early written documents. They are scheduled for 2012/13 within a French-German joint research project. Another new module is a glossary of the and early Arabic literature. For overcoming troubles in the presentation of early Arabic script a special font has been developed: The Coranica.
The project Corpus Coranicum began at the Berlin-Brandenburg Academy of Science and Humanities in 2007 with a planned duration of 12 years. The project aims at both a holistic edition of the Quran and also an extensive commentary. In addition to the Al-Azhar Quran edition from 1923/1924, this project will provide the reader with early written testimonies as well as oral reading variants that are manifested in early islamic literature.
Manuscripta
The project sees the module Manuscripta Coranica as following the tradition of G. Bergsträßers planned Apparatus Criticus, which due to Bergsträßers early death could never be realised. Thus the project aims at a new approach to the text of the Quran. Bergsträßer collected the oldest Quran manuscripts by travelling the Arabic world in the 1920s with a 35-mm camera.

Figure 1: A page from the Kodex Meknes from the collection of Bergsträßer
These photographs remained lost until members of the Corpus Coranicum found the filmstrips in 2008 (Higgins 2008). Immediately we began to digitize the images in levels of grey. The project can therefore present digitizations from Quran manuscripts in the module Manuscripta Coranica that are lost today. A database containing metadata that includes the range of verses in one image has been developed and filled. The early manuscripts have a high degree of ambiguity, as vocals and diacritics were used irregularly and different from today. Thus these manuscripts document the continuity as well as the development of the Arabic writing system.

Figure 2: Same page in the module Manuscripta Coranica
The Quran was revealed to Mohammed from God via the angel Gabriel beginning in 610 (western dating). Until 632, the year of Mohammed’s death, the divine revelations were mainly orally memorized and written on palm leaves. The Quran consists of 114 chapters that are called suras. Each sura consists of a different number of verses with a total number of 6326 verses. The length of the verses degrees from sura one to 114. The Corpus Coranicum aims at documenting the double string of the quranic textual history, as it was handwritten and orally (which was codified in later islamic sources) passed on next generations. So, beneath the module Manuscripta Coranica, which documents the handwritten tradition of text, the oral reading tradition of the Quran has to be documented as well.
Lectiones
This is the module Lectiones Coranicae, in which we present the different readings of the Quran. In this module only these variants that have phonetic effects, are collected. Each variant is assigned to one or more reader or the bequeathing person. A synoptical view on these variants looks like a score of the Quran.
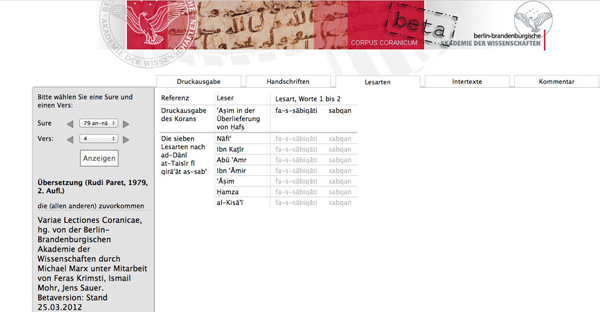
Figure 3: Lectiones Coranicae
Commentary
The commentary on each sura contains different parts. First, texts from the environment of the Quran like the bible, Talmud and early Arabic inscriptions, papyri and others have to be mentioned. We call these texts intertexts. Here one encounters a high diversity of different writing systems, such as Greek, Syrian, Pahlawi and others. Sources are therefore found in many different languages. With this collection of heterogeneous texts connected to each verse of the Quran the user will be able to draw a map of traditions that were mentioned in the holy text.
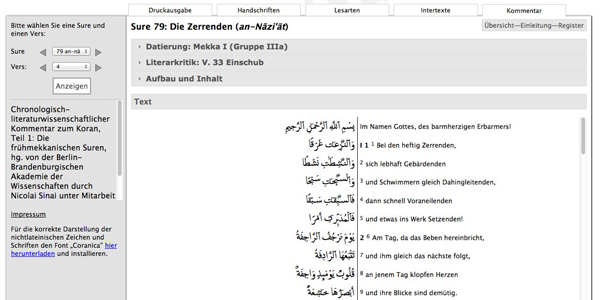
Figure 4: The module commentary on the Quran
The grammar in the suras is the theme of the second part of the commentary. A word can be explained through comparisons with other manifestations of the word in the Quran. In addition, the identification of Quranic loan words must be mentioned. In order to facilitate this work, a database Glossarium Coranicum has been developed. The formal structure of each sura is the subject of another part of the commentary. The literal appearance of oaths, revelations and other structural phenomena are recorded in this section, thus documenting the formal history of Quranic speech. After having captured the lexical, grammatical and literal characteristics of the sura, it is possible to identify insertions, in so far as they can be proofed following the interpolation hypothesis. The interpretation is the last part of the commentary for each sura. On the one hand each text can be assembled in different ways, reflecting the chronology of the sura’s formation. On the other hand the differences to the intertexts can be used to show the uniqueness of the sura.
The digital landscape
Coming to the digital environment of the project, we try to organize the information in different databases that provide the backbone of the Corpus Coranicum:
- Manuscripta Coranica
- Lectiones Coranicae
- Bibliographia Coranica
- Glossarium Coranicum
- Intertexts
- Quran itself
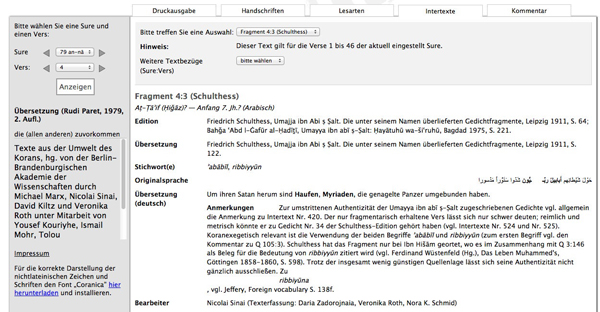
Figure 5: The module intertexts
The connection between these databases is the sura and the verse. It is thus possible to show all connected information for one verse: the manuscripts showing the verse, the intertexts of the verse and the loan words used in the verse. The commentary for each sura is stored in XML, following and extending the transcription rules of the Text Encoding Initiative. We therefore, have a heterogeneous digital information landscape, where different and yet separated information systems are bundled under one umbrella. Generally stated, the different cultures the project deals with are combined within this information system. The usage of different writing systems and languages are thus another challenge in the project. As available fonts were unable to represent ancient Arabic writings (the vocalisation points are orientated on modern Arabic writing systems) a special font had to be developed within the project, called Coranica, which we offer as well for download as open source.
Arabic digital philology is a young and emerging field in the digital humanities. Speech technologies like the Hopper of the Perseus project or the Buckwalter ensive arabic dictionary, remain unfulfilled. However, freshly published resources like the Lane dictionary can be used to broaden the perception of Arabic texts. In my presentation I will demonstrate the techniques and web-contents of the Corpus Coranicum, as the first results of the project goals are published in the first half of 2012. Thus the Quran will be presented for the first time as a digital reference system not only for the Quran itself, but as well integrating other sources from the early Arabic and old Ancient world. Thus, philology must make sense to the text itself (Pollock 2009).
References
Bergsträsser, G. (1993). Nichtkanonische Koranlesarten im Muhtasab des Ibn-Ginnī / von G. Bergsträsser. Egelsbach: Hänsel-Hohenhausen.
Higgins, A. (2008). The Lost Archive. Wall Street Journal. Available at: http://online.wsj.com/article/SB120008793352784631.html (accessed 25 March 2012).
Pollock, S. (2009). Future philology? The fate of a soft science in a hard world. Critical Inquiry. 35(4): 931-961.
Spitaler, A. (1935). Die Verszählung des Koran nach islamischer Überlieferung. München: Bayer. Akad. d. Wissenschaften.
Wansbrough, J. (2004). Quranic Studies: Sources and Methods of Scriptural Interpretation. London: Prometheus Books.