
In recent years, archival institutions storing historic handwritten document collections have been somewhat reluctant to invest in digitization (scanning). The reasons for this are threefold. Firstly, early, rigorous digitization campaigns of the past (1985-2000) were costly and sometimes disappointing. Secondly, the quality of Optical Character Recognition (OCR) techniques is very low for handwritten manuscripts. Thirdly, the digitization of historical documents and the permanent storage of the resulting digital images is costly. Such investments are generally only considered worthwhile if it is possible to access and browse the digitized material quickly and easily, in a manner which satisfies a large user base.
The Monk system was developed in answer to the afore-mentioned problem: the aim of this project is build an interactive search engine for browsing handwritten historical documents, using machine-learning and pattern classification. Ultimately, it should become possible to ‘google’ for a search-term in large collections of digitized handwritten document images. Traditional OCR fails in handwriting, because patterns are largely connected, noisy and difficult to read, even for humans. In addition, historical script types vary tremendously according spatio-temporal origins. Furthermore, traditional Automatic Handwriting Recognition (AHM) techniques require many examples of a single word or letter class from a single writer to be considered feasible in this case, and training occurs off line, in a lab or company. Therefore, an innovative new bootstrapping method based on user-based word labeling was developed to train a computer system, Monk, to read historical scripts (Zant, van der et al. 2009). This system has been used successfully in the first massive processing of early twentieth century handwriting in the Dutch ‘Cabinet of the Queen.’ The success of this endeavor stimulated the research in the direction of older, more difficult material.
A Difficult Case: the Leuven Alderman’s Rolls
The Leuven city archive is currently in the process of digitizing its collection of the Leuven Alderman’s rolls, early fifteenth century. This text is the urban record of voluntary jurisdiction and disputes settled by the Aldermen; individual cases are described in short legal acts. As a pilot study, the book of the year 1421 (MS SAL 7316, Leuven City Archive, Belgium) was ingested by the Monk system, with the aim of achieving handwriting recognition on the current Gothic minuscule these hundreds of pages are written in. Indeed, this is no easy feat, considering that contemporary humans need special training to be able to read this script. However, even if one – as a human – can decipher series of individual characters (letters, abbreviations, glyphs) in the text, this does not directly lead to understanding. Firstly, there is a linguistic barrier: the rolls are written mostly in Latin and occasionally in Middle Dutch. Secondly, in order to understand what the text means one needs much background knowledge about the type of text and the administration of justice in medieval Leuven. As the Monk system still makes many mistakes in its attempts to read the script of the Leuven alderman’s rolls, it seems that additional modeling is needed to improve results of computer-based reading.
Contextual Modeling: Language and Semantics
The idea of top-down linguistic support for bottom-up word hypotheses generated by a script classifier such as Monk – is not entirely new. The use of a statistical language model to improve offline handwriting recognition has been proposed (Zimmerman & Bunke 2004). However, the use of a general language model or syntax will not do in case of the Leuven Alderman’s rolls. Firstly, the text employs a register of highly artificial legal language. Secondly, no formal language models are existent for the Middle Dutch and Medieval Latin it employs and no encoded text corpus exists for the automatic generation of a ‘stochastic grammar’ (Manning & Schütze 1999).
Therefore, a semantic model was developed to support recognition by Monk in the rolls. While syntactic modeling may fail due to input variation and variability, semantics are invariably present in any utterance of language. A semantic framework can support both the human- and machine-based decoding. In the case of the Leuven Alderman’s rolls, meaning, i.e. higher knowledge levels, supports the recognition of words and letter forms at the lexical and orthographical level. Human readers, as opposed to digital document processors, sample text opportunistically and take into account contextual information eclectically (Schomaker 2007). To distinguish the /v/ from the /b/ in current gothic minuscule the human reader may rely on contextual information where an uninformed computer program cannot. More specifically, the interpretation of the ink patterns on a page is determined by an expectancy on what to find in the text. In case of an ‘IOU’, for instance, the reader expects to find, somewhere, the names of two persons, a sum of money, and possibly a date of payment. The more difficult the deciphering of patterns at the small scale, the more important is the role of such additional high-level information and expectation at a larger scale of observation: the semantics expressed by a text block of about a paragraph or administrative entry (‘item’) in the case of an administrative archive.
Semantic Support
During the present project a framework for disclosing the semantics contained in the digital image of the manuscript page was attempted. First, the accomplishments of historical philological method and manuscript studies were put into practice to create a ‘world model’ as introduced in the field of artificial intelligence (Schank 1975), specifying objects, their attributes and their mutual (abstract) relationships. Such a model is the necessary ‘historical backdrop’ for understanding the text. It includes vital information elements, such as the specific type of legal text and its place in the process of administering voluntary justice (Synghel G. v. 2007; Smulders 1967).
Secondly, a typology of types of acts was formulated, with the help of scholarship on the comparable alderman’s rolls of Den Bosch (van Synghel 1993; Spierings 1984). This typology of acts functions as a fundamental part of the interpretative apparatus. Exhaustive knowledge about which key phrases encode for a certain type of act, immensely help in identifying the real-life legal transaction an act refers to. However, the gap between high level meaning and the 2-dimensional format of the document still needs to be bridged.
Towards a Formal Semantic Modeling of the Act
In the research field of document structure and lay-out analysis a distinction is commonly made between ‘geometrical layout’ and ‘logical content’; referring to specific visual regions on the page, and their content and/or functional label, and reading order. The logical structure can then be mapped to the relevant geometrical regions on the page, to achieve optimal analysis of the document image (Haralick 1994; Namboodiri & Jain 2007).
During the second phase of the project ‘The Legal transactions’ a formal semantic model was constructed based on the basic distinction between geometrical and logical representation, viz. digital image and semantic content respectively. The geometrical branch is subdivided in polygonal regions of interest (ROIs), which again break down into smaller nodes such a ‘ink’ and ‘background’. The logical branch describes the structure of semantic content in legal acts. By interlinking the relevant nodes the two branches using unique identifiers (idROIs), it becomes possible to cross-refer between manuscript page and content.
Several XML schemes for layout and content modeling exist; however, to date none of these standards is designed for handwritten text (Stehno, Egger, & Retti 2003; Bulacu, van Koert & Schomaker 2007). These formalisms are suitable for regular, printed text and rectangular elements. Due to the erratic nature of the page layout and line formation in medieval handwritten manuscripts a system of polygonal visual regions connected to the semantic model by unique identifier codes needs to be used for Monk, comparable to layout modeling tools such as TrueViz and GEDI.
None of these formalisms provide an easy solution for linkage between layout and the semantic level: such a connective layer needs to be developed for each particular document type. If it is elaborated in Web Ontology Language (OWL) or Resource Description Framework (RDF), the ‘aldermen’ semantic model can be used to train Monk to recognize the structural elements of acts and formulate hypotheses about their meaning. Conversely, the same model may assist in interactive teaching of humans as to where to locate the desired information in an act. The most exciting finding of this study was that superficial low-level ink patterns and glyphs can be used to infer clues about the semantic content, which in turn constrains the large number of possible text interpretations.
As an example, a selection of the most basic logical components in the legal acts was made:
- the start of a new act is signaled by ‘Item’ (X0,Y0)
- the semantic anchor reveals the type of legal transaction (X1,Y1)
- names of presiding aldermen and (X2, Y2)
- the date give the act legal force (X3,Y3)
- the ‘solvit’ glyph signals that a charter was issued and seal-money paid (X4,Y4)
From a number of pages, 22 acts were manually analyzed in terms of the geometric distribution of element in the horizontal plane. Based on the relative geographical location of these semantic elements and their probability of occurrence in the plane, Monk may weigh his bottom-up hypotheses using a Bayesian model (see fig. 1). The small sample includes only the most basic semantic elements on the page; many more may be added to improve recognition accuracy.
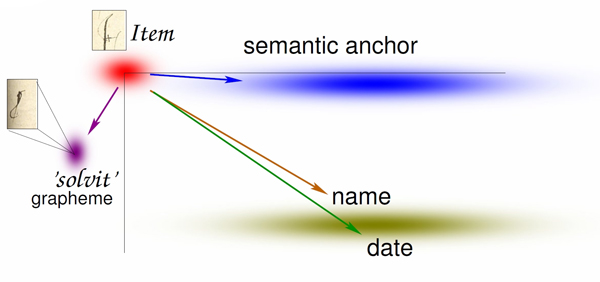
Figure 1
References
Balacu, M., R. van Koert, and L. Schomaker (2007). Layout Analysis of Handwritten Historical Documents for Searching the Archive of the Cabinet of the Dutch Queen: Proceedings of the 9th International Conference on Document Analysis and Recognition. Curitiba, Brazil, September 2007.
Haralick, R. M. (1994). Document Image Understanding: Geometric and Logical Layout: Proceedings of the Computer Vision and Pattern Recognition Conference. Seattle, June 1994.
Manning, C. D., and H. Schütze (1999). Foundations of Statistical Language Processing. Cambridge, Mass.: MIT Press.
Namboodiri, A., and A. Jain (2007). Document Structure and Layout Analysis. B. B. Chaudhuri (ed), Digital Document Processing. London: Springer, pp. 29-48.
Schank, R. C. (1975). Conceptual Information Processing. Amsterdam: North-Holland Publishing Company.
Schomaker, L. (2007). Reading Systems: An Introduction to Digital Document Processing. In B. B. Chaudhuri (ed), Digital Document Processing. London: Springer, pp 1-26.
Smulders, F. W. (1967). Over het Schepenprotocol. Brabants Heem 19: 159-65.
Spierings, M. (1984). Het Schepenprotocol van’s-Hertogenbosch, 1368-1400. Tilburg: Stichting Zuidelijk Historisch Contact.
Stehno, B., A. Egger, and G. Retti (2003) METAe – Automated Encoding of Digitized Texts. Literary and Linguistic Computing, 18: 77-88.
Synghel, G. van (1993). Het Bosc’’ Protocol: een Praktische Handleiding. ’s-Hertogenbosch: Werken met Brabantse bronnen 2.
Synghel, G. van (2007). “Actum in camera scriptorum oppidi de Buscoducis”: De stedelijke secretarie van’s-Hertogenbosch to ca. 1450. Hilversum: Verloren.
Zant, T. van der, et al. (2009). Where are the Search Engines for Handwritten Documents. Interdisciplinary Science Reviews 34: 228-39.
Zimmerman, M., and H. Bunke (2004). Optimizing the Integration of a Statistical Language Model in HMM based Offline Handwriting Text Recognition: Proceedings of the 17th International Conference on Pattern Recognition. Cambridge, UK, August 2004.