
Introduction
The HyperMachiavel project started with the idea of a tool that would aid research communities comparing several editions of one text and in particular comparing translations.
The Italian studies department (Triangle laboratory) at ENS de Lyon has been working for many years on fundamental texts, from Machiavelli, Guicciardini and other contemporary followers, that put forward new political concepts throughout Europe in the 16th century. The question addressed in the project was mainly about the transfer of these concepts from one language to another, and especially their reception in France. The first aligned corpora tested in our tool gathers different editions of Machiavelli’s Il Principe, the princeps edito from Blado in 1532 and the first four French translations of the 16th century.
Inspired by machine translation and lexicographic domains, the system presented in this paper proposes an annotation environment dedicated to the edition of lexical correspondences and offers different views to assist humanities researchers in their interpretations of the quality and the specificities of translator’s work.
Viewing and Searching in Aligned Corpora
Synoptic View
To be able to identify lexical correspondences, machine translation tools usually propose a frame of two panels, one for the source text and the other for the target text. The visualized interface is meant for annotators to easily revise the results obtained from automatic word alignment. In general it only considers a pair of texts at a time.
In the world of digital editions, text comparison has always been of great interest and the request to view diplomatic vs normalized transcriptions, or simply different editions of one text increases all the more that digital data become truly available. Systems such as the Versioning Machine (Schreibman et al. 2007) already offers parallel views for TEI aligned corpora with no constraint on the number of displayed texts. Being able to take into consideration several target versions was an important starting point when designing HyperMachiavel. Therefore the main panel offers a ‘Parallel view’ (see Fig. 1) to interact with processes that need global context visualization (e.g. concordancer results).
Alignment
To deal with text alignment, many tools working with pair of texts (bitext2tmx, alinea or mkAlign1, Fleury et al. 2008) uses statistical measures of co-occurrence or combines word distribution algorithm with cognates detection. Although original investigation on automatic alignment has been proceeded for non modern texts like in the Holinshed Project (Cummings & Mittelbach 2010), our focus was to fulfill the need for editing and controlling lexical correspondences. Exploring these techniques will be done in a second development phase but for the moment, HyperMachiavel imports aligned corpora encoded in XML-TMX or XML-TEI and proposes a manual alignment feature for additional text files.
Because old edition texts usually present great variability in the lexical forms, we favored a computer-aided system for bilingual search and put efforts in the lexicography work environment.
Lexicography and Lexical Tagging
Linguistic annotation tools make use of external dictionaries to tag texts but cannot be applied on old texts per se. Combining this process with the user’s analysis of the text to build its own lexical resource, either by bringing corrections to the model or proposing partial tagging, is a necessary condition for our study. Recent work conducted by Lay et al. 2010 have also emphasized the user’s interaction in the lexical exploration and offers customization of lexical resources. HyperMachiavel follows that path by presenting tokenizer’s choice (among which TreeTagger java implementation by Helmud Schmid) and a general framework to consolidate endogenous or external lexical resources that would work in harmony with the defined corpora.
Information obtained from tokenization like category, lemma, word onset and offset localisation in the texts are registered in XML files. A full-text search engine, specially designed for the tool, uses this information, so does the ‘Vocabulary view’ listing all the forms for each language in the corpora. This view displays frequency information by text (see Fig. 2) and brings a first impression on lexical distribution among versions, or authors in our case.
The use of concordancer (Key Word In Context) that classically links dictionary entries to corpora occurrences is central in the system (results of monolingual search or after a selection from the ‘Vocabulary view’, e.g. Fig. 3). As for equivalences detection are concerned, some authors have shown that bilingual concordancers (ParaConc; Barlow et al. 2004; ConcQuest; Kraif 2008) are very helpful. However viewing results of bilingual search with concordancers in our case is not sufficient. As we want to compare numerous source and target texts, a ‘Parallel Indexes view’ has been designed and is described hereafter.
Exploring Equivalences
Equivalences Detection and Validation
Annotating equivalences is a long process and a semi-automatic scenario has been introduced with the bilingual search. Results from that search are displayed in the ‘Parallel indexes view’ (see Fig. 4). Some results will show co-presence in an aligned segment of at least one source and target searched items, but source or target occurrences could be found alone.
When the user is faced with empty results (source or target), the ‘Parallel view’ helps detect other potential equivalence expression. In some cases, it could mean that no translation has been given or that the occurrence belong to another semantic group (e.g. homonyms, polysemes).
Validation of real equivalences versus suggested equivalences from the bilingual search, is done by checking the lines. However manual completion is often required, especially when source or target refer to specific expressions or to other lexical terms that were not used in the search.
Graph Visualizations
Exploring edited equivalences can be pursued in other environments like excel or any data analysis programs but HyperMachiavel has developed some feature to highlight thematic groups of equivalences and show stylistic differences between translations.
For each dictionary entry, one can ask to see validated target equivalences. Information about their frequency and distribution between versions of text help the user evaluate translator’s appropriation of the source text (see Fig. 5). Graph visualizations illustrate the same information but the user can go further and ask to see equivalents of equivalents until no new information is provided. Groups of equivalences usually appear and interrogate the user on the conceptual themes exposed in the corpora.
In the current aligned corpora, we have noticed that most French translators of Il Principe depict the polysemic and complex reality of new political concepts at that time by giving various lexical equivalences. Yet one of the translators prefers to steadily deliver concepts with almost unique translation (e.g. ‘stato’ with only ‘estat(s)’) perhaps believing that the rest of the text would do the rest.
Conclusion
This paper presents the state of development of HyperMachiavel2, a tool distributed under a french open-source licence (Cecill-B). Although the demonstration was done with only french-italian texts the tool was defined to support manual edition of equivalences for aligned multilingual corpora and lexicography work.
Providing import and export formats recommended by the digital humanity community ensure reuse of corpora in other environment such as text mining platform using the full complexity of TEI encoded corpora (e.g. TXM3 , Heiden 2010). Use of automatic alignment algorithms will be tested with another aligned corpora based on Machiavelli’s The Art of War-translations. The idea is to extend our tool features for comparable corpora (different texts of authors highly influenced by Machiavelli’s work).
Funding
The work presented here is carried out within the research project (2008-2011) ‘Naissance, formes et développements d’une pensée de la guerre, des guerres d’Italie à la paix de Westphalie (1494-1648)’, funded by the French Agence Nationale Recherche.
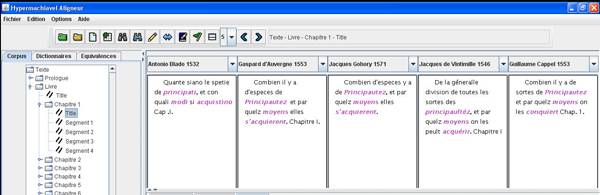
Figure 1: ‘Parallel view’ of the aligned texts (right panel) and ‘Corpus view’ are showing the text structure common to all versions (left panel)
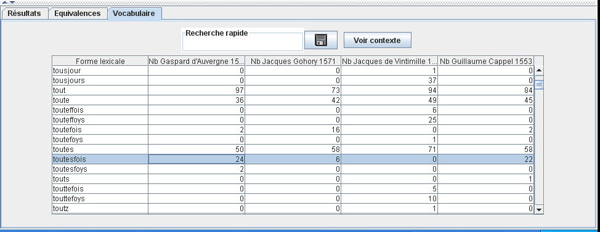
Figure 2: The ‘Vocabulary view’ presents lexical forms and their frequency (number of occurrences) in the different aligned texts
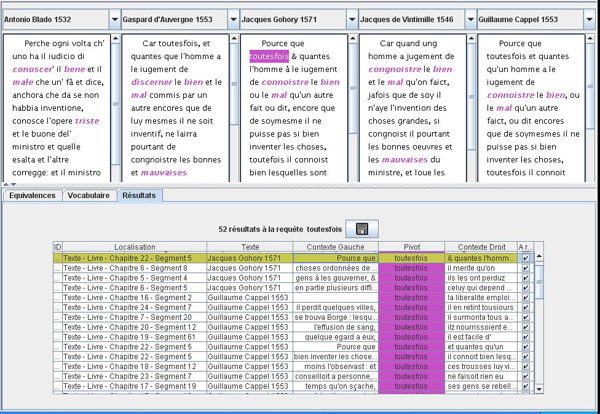
Figure 3: The ‘KWIC view’ shows occurrences of the french old form ‘toutesfois’
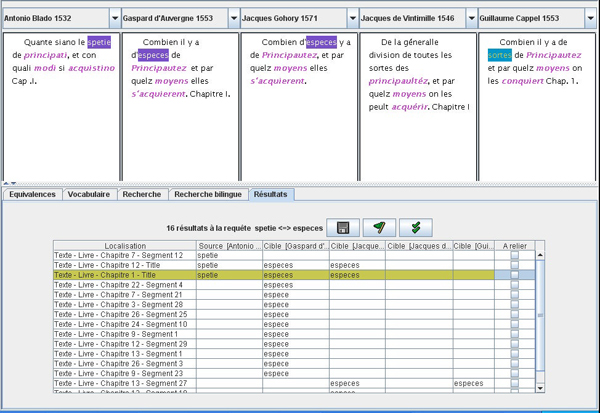
Figure 4: The ‘Parallel Indexes view’ shows searched source and target expressions that appear in the same localization. The bilingual search example was performed with ‘spetie’ as source expression and ‘espece(s)’ as target expressions
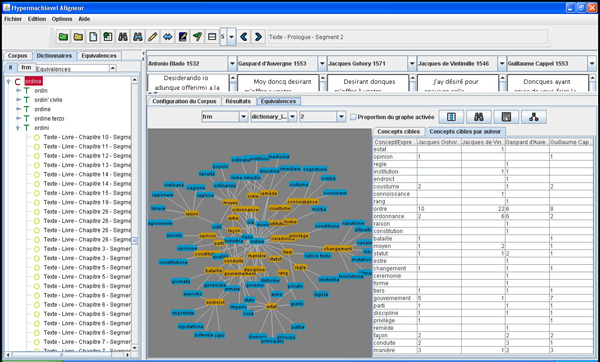
Figure 5: Views of French equivalents for the Italian concept ‘ordine’
References
Bowker, L., and M. Barlow (2004). Bilingual concordancers and translation memories: A comparative evaluation. In E. Y. Rodrigo (ed.), Proceedings of the Second International Workshop on Language Resources for Translation Work, Research and Training. Geneva, Switzerland, August 28, 2004, pp. 70-83
Cummings, J., and A. Mittelbach (2010). The Holinshed Project: Comparing and linking two editions of Holinshed’s Chronicle. In Citation Information. International Journal of Humanities and Arts Computing 4: 39-53 DOI 10.3366/ijhac.2011.0006, ISSN 1753-8548, October 2010.
Fleury, S., and M. Zimina (2008). Utilisations de mkAlign pour la traduction philologique. Actes JADT 2008, Journées Internationales d’Analyse Statistiques des Données Textuelles, Lyon, 2008.
Heiden, S. (2010). The TXM Platform: Building Open-Source Textual Analysis Software Compatible with the TEI Encoding Scheme. In 24th Pacific Asia Conference on Language, Information and Computation, Sendai, Japan 2010.
Kraif, O. (2008). Comment allier la puissance du TAL et la simplicité d’utilisation ? L’exemple du concordancier bilingue ConcQuest. In Actes JADT 2008, Journées Internationales d’Analyse Statistiques des Données Textuelles, Lyon, 2008.
Lay, M.-H., and B. Pincemin (2010). Pour une exploration humaniste des textes : AnaLog. In Actes JADT 2010, Journées Internationales d’Analyse Statistiques des Données Textuelles, Roma, 2010.
Schreibman, S., A. Hanlon, S. Daugherty, and T. Ross (2007). The Versioning Machine v3.1: A Tool for Displaying and Comparing Different Versions of Literary Texts. In Digital Humanities 2007. Urbana, Illinois. Jun. 2007.
TEI Consortium. (2008). TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 1.1.0.,
4th July. L. Burnard and S. Bauman, eds., TEI Consortium. http://www.teic.org/Guidelines/P5
Notes
1.Software ‘alinea’ is developed by O. Kraif ( http://w3.u-grenoble3.fr/kraif/index.php?Itemid=43&id=27&option=com_content&task=view), ‘bitext2tmx’ (http://bitext2tmx.sourceforge.net ) by S. Santos, S. Ortiz-Rojas, M. L. Forcada and now R. Martin, and ‘mkAlign’ by S. Fleury (http://www.tal.univ-paris3.fr/mkAlign)
2.The software can be downloaded at http://hypermachiavel.ens-lyon.fr
3.TXM is a collaborative, open-souce software initiated by S.Heiden and the textometrie project members (http://textometrie.ens-lyon.fr/)