
Introcuction
This poster provides a summary of our ongoing project for providing integrated access to Japanese multiple digital libraries, archives, and museums. The main goal to construct a federated access system for Japanese humanities databases, which searches multiple databases in parallel and provides on-the-fly integration of the results, has required the system to deal with heterogeneous metadata schemas in various formats. Aggregation and integration of the retrieved results in English and Japanese are complicated if a search needs to be performed from multilingual sources. Ukiyo-e, Japanese traditional woodblock printing, is known worldwide as one of the fine arts of the Edo period (1603-1868). Many museums and organizations in Japan as well as in western countries hold numerous Ukiyo-e prints in their collections. As a result of worldwide digitization over the last decade, many cultural institutions including libraries, archives, and museums started to expose digitized images of Ukiyo-e prints on the Internet. How to find the necessary information effectively from multiple databases is becoming an essential issue for users. In other words, users need an efficient way of searching multiple databases, especially when it is getting more difficult to know which museum has a particular Ukiyo-e print. Thus, federated search of multiple Ukiyo-e databases scattered around the world is a feature expected by humanities researchers of Japanese culture. This poster proposes a method of integrated multilingual access to heterogeneous Ukiyo-e databases for improving the search efficiency.
Related research
In LODAC (Linked Open Data for Academia) Museum, which is a part of Lod.ac project, Kamura et al. (2011) aimed to connect Japanese museums using Linked Open Data (LOD). The LODAC Museum has an online system1, which can search and browse various data of Japanese museums in Japanese using the concept of Linked Data2. In a similar research of the eCultura project, Cornejo et al. (2010) introduced a set of services and applications to access and integrate diverse web-based contents of the cultural domain.
However, we propose a different approach, which has the following three differentiations. First, instead of collecting data from each database, we create links from the search results dynamically. Second, we access not only Japanese databases but multilingual databases from all over the world. Third differentiation is to use authority data for listing related items. We apply our approach to the federated search system for Ukiyo-e databases that we are developing.
Proposed approach
Federated searching system
We are developing a prototype federated searching system for Ukiyo-e prints, which retrieves multiple and heterogeneous back-end databases (Batjargal et al. 2011). In the proposed system, remote databases can be searched and retrieved simultaneously via the federated search protocols such as Search/Retrieve Web service (SRW), Search/Retrieve via URL (SRU), etc. SRU servers return a result set represented in XML, when a search request is received. In addition, web databases are accessible using ‘web/screen-scraping’ techniques that process a list of search results by reading and extracting data from HTML. At present, our proposed system is capable of retrieving the collections of the Library of Congress (approx. 2,740 Ukiyo-e prints), the National Diet Library (NDL) of Japan (approx. 10,000 Ukiyo-e prints), the British Museum (approx. 15,000 Ukiyo-e prints), the Boston Museum of Fine Arts (approx. 57,000 Ukiyo-e prints), the Victoria and Albert Museum (approx. 38,000 Ukiyo-e prints), and the Ukiyo-e database of the Art Research Center of Ritsumeikan University (approx. 12,500 Ukiyo-e prints). Figure 1 shows the conceptual architecture of the existing federated searching system for Ukiyo-e databases. Figure 2 shows the screenshot of sample search results.
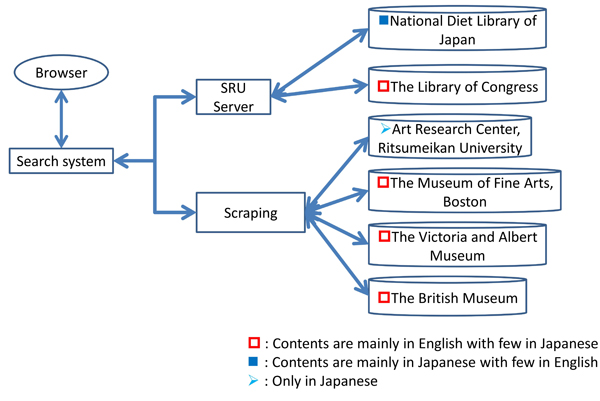
Figure 1: Conceptual architecture of a federated searching system for Ukiyo-e prints
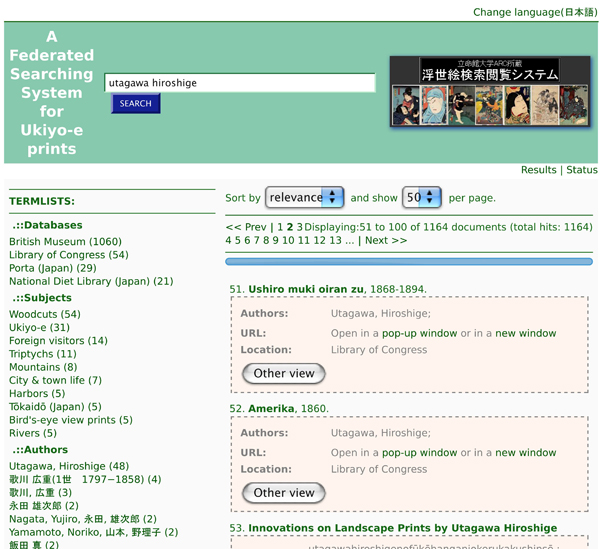
Figure 2: Sample search results
Utilizing Linked Data
This section discusses our achievements that utilize Linked Data to providing integrated access to multilingual Ukiyo-e prints from all over the world. Linked Data is a paradigm of constructing structured data, which can be read automatically by computers. Linked Data consists of the interlinked data sets, e.g. have relationships between resources. Each resource is identified by a unique URI (Uniform Resource Identifier), and represented in RDF (Resource Description Framework) format. RDF is a data model, in which any resource can be represented by a set of property and value pairs that make statements about that resource. There are three reasons of using Linked Data in our approach. Firstly, Linked Data could be used to link related data in various databases. Taking advantages of a simple model of RDF, we could create various links by combining various RDF data. Secondly, besides linking related data, Linked Data could enable accessing to diverse databases easily. Prior to Linked Data, users were usually accessing each database one-by-one. However, by using the links of related data, users would be able to access to related data in multiple databases with less trouble. Thirdly, Linked Data could help users to discover some further relationships between individual data.
We utilize the name authorities and subject headings of NDL of Japan, i.e., Web NDL Authorities3, for obtaining data in RDF. In Web NDL Authorities, name authorities and subject headings can be searched via SPARQL (Simple Protocol and RDF Query Language), which is an RDF query language for searching and manipulating data in RDF format. An authority data for a heading (e.g. personal name, subject, etc.) contains aliases and synonyms of the heading, and information showing the reason for being selected as the heading. In our approach, we use the authority data for identifying a particular person from different representations of the personal name in different databases. The subject heading also distinguishes words that have same representations but different meanings. In an example of authority data as shown in Figure 3, the heading ‘Shakespeare, William, 1564-1616’ has three different representations in Japanese. An authority data of NDL of Japan contains personal names, family names, corporate names, place names, uniform titles, and general subjects for a certain heading. At present, we utilize only personal names and general subjects in our approach.

Figure 3: An example of an authority data
The proposed approach in action
In this section, we explain about the proposed system that aims to realize integrated multilingual access to Ukiyo-e prints in the world. Outline of the proposed system is shown in Figure 4. At first, in the step ‘Search (1)’, our system acquires the search results when a user performs a search in a federated searching system. Then in the step ‘Select (2)’, the system extracts the appropriate authority data for a certain record. In the step (3), the system finds the variants or aliases for that authority data by using SPARQL. After that, the system searches diverse databases by using the variants or aliases as queries. Finally, the system shows the refined retrieved results (4) with the links for further search (5). In general, the user will be able to access to other data easily by using the authority data of the aliases.
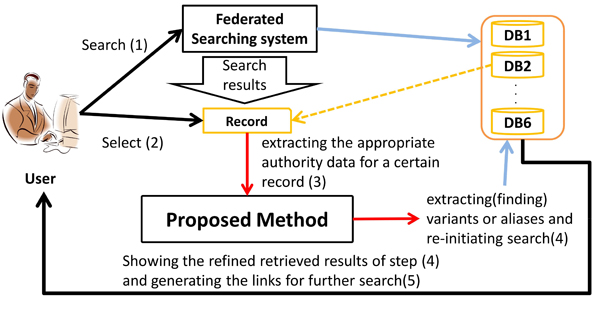
Figure 4: Outline of the proposed system
For instance, as shown in Figure 5, if a user searches using a query ‘Hiroshige Utagawa’, then our system finds the aliases ‘Hiroshige Ando’ and ‘Hiroshige Ichiryusai’ by using an authority data of ‘Hiroshige Utagawa’. Using the aliases of ‘Hiroshige Utagawa’ (e.g. ‘Hiroshige Ando’ and ‘Hiroshige Ichiryusai’) our system will show further results.
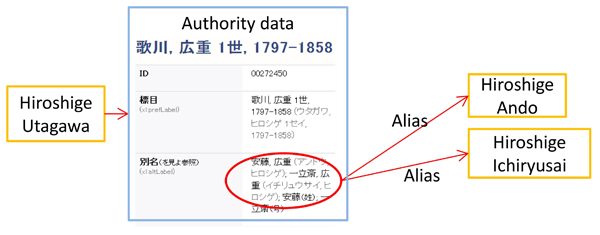
Figure 5: An example of integrated access
Furthermore, some authority data in Web NDL Authorities has a link to Library of Congress Subject Heading (LCSH). Therefore our system can also provide cross-language access between Japanese and English as shown in Figure 6. Using a link from NDL Subject Headings (NDLSH), the proposed system can generate further links. In this way, users will be able to access to more records with ‘Hashirae’, ‘Pillar Prints’ and ‘Ukiyo-e’ for a given query input ‘ukiyo-e’ by generating the links for ‘Ukiyoe’ by using LCSH. Even if the user has no knowledge about the term ‘Hashirae’, he or she can access them easily and efficiently.
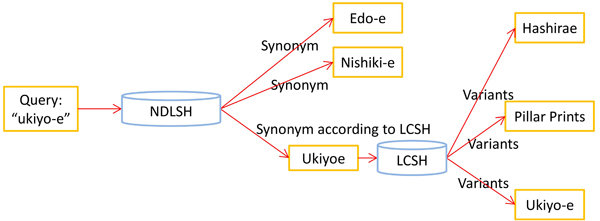
Figure 6: An example of multilingual access using Subject Headings
Evaluation of the system
In this section, we discuss our preliminary evaluation of the proposed system. In order to evaluate the usefulness of the system, we calculated the accuracy of the aliases obtained by the proposed system by manually checking whether the records retrieved using the aliases are actually about the same person as the original query (Figure 7). Table 1 shows the results of 6,923 retrieved records for several Ukiyo-e painters. The proposed system achieved the accuracy rate of 99.89% for the aliases of Ukiyo-e painters with full names. The accuracy rate drops to 89.91% for the aliases that consist of either first name or last name of Ukiyo-e painters, because of increased ambiguity in short strings. The overall accuracy rate was 95.45%, which should be enough for most purposes.
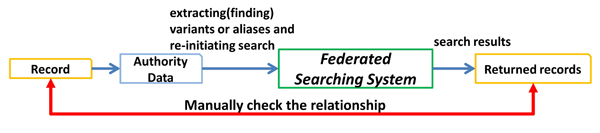
Figure 7: Evaluation process of the proposed system
| Type of alias | Number of the records | Number of the records of the same person | Accuracy rate |
| Full name | 3,840 | 3,836 | 0.9989 |
| Either first name or last name | 3,083 | 2,772 | 0.8991 |
| Total | 6,923 | 6,608 | 0.9545 |
Summary
In this poster, we proposed a technique using Linked Data in order to realize multilingual integrated access to multiple digital archives. One of the unique features of our proposed approach is that we utilize authority data to deal with the problem of different representation of data in different databases, as well as to generate cross-language links between databases. We believe such a system will help users to find new knowledge, and will also facilitate new directions in humanities research. Our future work include extending our system to other humanities digital archives, and user evaluation of the prototype system.
Funding
This work was supported in part by MEXT Grant-in-Aid for Strategic Formation of Research Infrastructure for Private University ‘Sharing of Research Resources by Digitization and Utilization of Art and Cultural Materials’ [Grant Number: S0991041].
Reference
Batjargal, B., F. Kimura, and A. Maeda (2011). Metadata-related Challenges for Realizing Federated Searching System for Japanese Humanities Databases. Proceedings of the 11th International Conference on Dublin Core and Metadata Applications. The Hague, Netherlands, September 2011, pp.80-85.
Kamura, T., F. Kato, I. Ohmukai, H. Takeda, T. Takahashi, and H. Ueda (2011). Study support and integration of cultural information resources with Linked Data. Proceedings of the Second International Conference on Culture and Computing. Kyoto, Japan, October 2011, pp. 177-178.
Cornejo, C. M., I. Ruiz-Rube, and J. M. Dodero (2010). eCultura, a semantically-enriched web-based approach to manage cultural content. Proceedings of the IEEE International Conference on Information Reuse and Integration, IRI 2010. Las Vegas, NV, August 2010, pp. 126-131.
Notes
2.http://www.w3.org/DesignIssues/LinkedData.html