
Czmiel, Alexander, Berlin-Brandenburg Academy of Sciences and Humanities, Germany, czmiel@bbaw.de Jürgens, Marco, Berlin-Brandenburg Academy of Sciences and Humanities, Germany, juergens@bbaw.de
Introduction
The construction of the Digital Knowledge-Store intends to collect and bundle all digital resources of the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW)1. It extends the existing infrastructure for publishing Digital Humanities knowledge resources in order to increase the visibility of the Academy’s research activities in the World Wide Web.
The BBAW is an institution with a long tradition in humanities research. It hosts various humanities long-term projects, which also do research on textual resources in many different languages from all over the world and any historic period. These projects generate research results that are also published digitally and include a variety of different resource types ranging from digital and interactive scholarly editions over collections of databases and images to multimedia content. These digital resources are unique and contain high quality content, for example, digital publications of medieval charters, ancient inscriptions, stained glass studies, manuscripts and much more. The variety of research content and data formats lead to the desire to build a centralized access point to all digital resources of the BBAW.
During the last decade the BBAW was deeply involved in the development of methods, tools, publications and frameworks of digital media and digital resources for scholars in the humanities. With the foundation of the TELOTA2 (The Electronic Life Of The Academy) working group ten years ago, the Academy became an active part of the ongoing research and development in the field of Digital Humanities. The main tasks of TELOTA are to evaluate and discuss the possibilities that digital technologies offer scholars working at the academy, and to develop tools and digital resources in close collaboration with the Academy’s numerous research projects. Hence TELOTA is also responsible for the development of the Digital Knowledge-Store.
The proposed paper will present the Digital Knowledge-Store of the Berlin-Brandenburg Academy of Sciences and Humanities and show possibilities and methods in the development of an interdisciplinary virtual research environment containing a high diversity of content, languages, data formats and objects.
The Digital Knowledge Store of the Academy
The work on the Digital Knowledge-Store was started in 2009 by the TELOTA working group of the Academy. During the current project phase, which started in September 2011 and is funded for three years by the Deutsche Forschungsgemeinschaft (German Research Foundation)3, it will be improved with extended metadata for better interoperability, a search component based on linguistic methods, and an innovative dialog based user interface. The Knowledge-Store aims to be an infrastructure that offers an easy to use but powerful interface, machine readable APIs and web services for translating queries and analyzing multilingual texts. By connecting the resources semantically with the means of linguistic analysis, text mining and semantic web techniques the infrastructure will support interdisciplinary research in- and outside of the Academy.
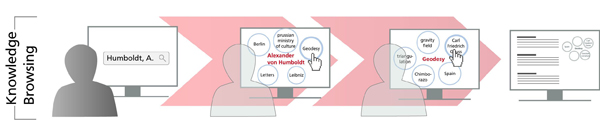
A dialog-based browsing through the Knowledge-Store
The potential of the Knowledge-Store lies in its way of dealing with the process of searching. One can think of the interface as a way rather to interact with the Knowledge-Store than just a query-answer process. The dialog based retrieval interface, the Knowledge-Browser, is conceptually a completely new development and tries to detach from traditional search interfaces by developing entirely new finding strategies. The Knowledge-Browser can be seen as a tool that enables an interactive step-by-step process of computer aided information retrieval.
A possible scenario would be a researcher who has a question about a certain topic but who does not know the BBAW project which could hold the answer. In that case the Knowledge-Store is the tool to solve this problem. The scholar starts the search with a query on a certain subject. In every following step he will receive qualified links to resources which contain the query term or conceptually related terms out of all the Academy’s digital resources. With every further step the scholar can browse a related term on the basis of the received results in a different context. As the resources will be linked semantically, every step of the query process offers a new query context. Hence the knowledge browsing is an interactive and multilevel process, which makes implicit connections between different internal and external resources explicit.
Rather than just giving the user the possibility to reduce the search results by filtering, as faceted search interfaces do, it extends the result by offering semantic recommendations for data and documents which were not present in the previous search results. On the basis of these connections the user can search overall in projects and even external project resources to find not only the desired answer but the queried term in different contexts and meanings which will lead to more meaningful connections between the research contexts which were not visible before.
Challenges and Solutions
The challenges result mainly from the heterogeneous resources which are stored in the various repositories and databases hosted by the BBAW. By defining a metadata scheme for all the different resources in the Academy the Knowledge-Store will provide a basis for the extraction of information by the Knowledge-Browser and a connection to related external projects. This supports interoperability between research data of the BBAW and projects such as Europeana4, Deutsche Digitale Bibliothek5, DARIAH6 or CLARIN7. The existing metadata is based on the Metadata Object Description Schema (MODS)8. It provides the basic information for search criteria and the description of the resource. For extending the metadata the Europeana Data Model (EDM)9 will be used to allow sophisticated connections of various heterogeneous resources. With extended metadata the Digital Knowledge-Store is prepared to provide linked open data to be part of the Web of Data10.
On the level of linguistic analysis an important problem to solve is that the multilingual textual resources in a major part do not follow a normalized orthography or a consistent language space. For the written German language of the 19th century the German Text Archive (DTA)11 and the Digitales Wörterbuch der Deutschen Sprache (DWDS)12 provide appropriate tools for an index based solution. For ancient Greek and Latin texts a cooperation with the Max Planck Institute for the History of Science13 is established to further the integration of the Donatus / Hopper software package14. Donatus is capable of handling texts in Greek and Latin as well as Arabic, German, English, French an others. These services are used for automated lemmatization and stemming as well as text-mining. In combination with Semantic Web technologies such as RDF15 and RDFa16 or ontologies, this results in basic semantic retrieval possibilities which enables the researcher to gain new knowledge by a process of searching in different contexts of the resources.
Additionally the Knowledge-Store aims to make all digital textual resources of the Academy accessible as full texts. Therefore it is important to build up an index which is prepared for a search based on linguistic methods, text mining and semantic information retrieval. This index is prepared using the aforementioned services for a search in corpora of different languages and in historic writings as well. The index uses a Lucene17 / Solr18 – Framework in combination with XQuery and XSLT-scripts to transform XML-Data and to update the index. Furthermore it is intended to integrate a tool which allows querying the full text without background knowledge of a certain language. This would be possible by sending a query via REST to a translation web service endpoint in order to receive a translated search term. There are several possible translation APIs available. Among those are the Microsoft BING Translation API19 and the Google Translate API20 which both provide a translation service that automatically translates text from one language to another.
Future prospects
The Knowledge-Store will enable a new way of querying humanities resources. The combination of the Academy’s resources, the Knowledge-Browser and the development of information extraction tools will lead to an infrastructure which allows to put the knowledge of the Academy’s different projects in different contexts. The Knowledge-Store will be build on open source technologies. On the same time it will realize by these means an interoperable infrastructure which can show new possibilities in the usage of Digital Humanities techniques. It guides the humanities scholar to new ways of thinking about the projects contexts by interconnecting and intercontextualizing the research resources in the BBAW. In developing a semantically interlinked base of resources which is capable of gaining knowledge by querying information in various contexts of the Academy’s projects, the Knowledge-Store will serve as a part of the realization of the Web of Data as well as it can be an exemplary project to establish a work flow for the integration of external infrastructure projects into one single endpoint.
A prototype version of the Knowledge-Store which does not include the Knowledge-Browser can be found at http://www.bbaw.de/en/telota/resources/dkb.
A much more developed interface will be available at conference time.
References
Bellamy, C. (2010). What is eResearch in the Arts and Humanities. http://www.craigbellamy.net/2010/04/07/what-is-eresearch-in-the-arts-and-humanities/ (accessed 9 March 2012).
Brock, T. (2010). ReThinking Digital Social Media for Digital Humanities and Community Engagement. http://dirt.terrypbrock.com/?p=1116 (accessed 9 March 2012).
Carusi, A., and T. Reimer (2010). Virtual Research Environment Collaborative Landscape Study. http://www.jisc.ac.uk/publications/reports/2010/vrelandscapestudy.aspx (accessed 9 March 2012).
DINI (2009). Informations- und Kommunikationsstruktur der Zukunft. http://www.dini.de/fileadmin/docs/DINI_thesen.pdf (accessed 9 March 2012).
Dallmeier-Tiessen, S., et al. (2009). Positionspapier Forschungsdaten. Arbeitsgruppe Elektronisches Publizieren. http://edoc.gfz-potsdam.de/gfz/get/13230/0/a271566a9d9f48030ee78e01ceae7138/13230.pdf (accessed 9 March 2012).
Davidson, C. N. (2008). The changing profession – Humanities 2.0: Promise, Perils, Predictions. Publications of the Modern Language Association of America 123(3): 707-717.
De Virgilio, R. (2010). Semantic Web information management: a model-based perspective. Springer.
Heath, T., and C. Bizer (2011). Linked Data: Evolving the Web into a Global Data Space. San Rafael, CA: Morgan & Claypool.
Key Perspectives Ltd (2010). Data Dimensions. Disciplinary Differences in Research Data Sharing, Reuse and Long term Viability. http://www.era.lib.ed.ac.uk/bitstream/1842/3364/1/SCARP SYNTHESIS.pdf (accessed 9 March 2012).
Murray-Rust, P., et al. (2010). Panton Principles. Principles for Open Data in Science. Open Knowledge Foundation. http://pantonprinciples.org/ (accessed 9 March 2012).
Neuroth, H., et al. (2009). Virtuelle Forschungsumgebungen für e-Humanities. Maßnahmen zur optimalen Unterstützung von Forschungsprozessen in den Geisteswissenschaften. Bibliothek, Forschung und Praxis 33(2): 161-169.
Rees, J. (2010). Recommendations for independent scholarly publication of data sets. Creative Commons Working Paper. San Francisco.
Sierman, B., B. Schmidt B., and J. Ludwig (2009). Enhanced Publications: Linking Publications and Research Data in Digital Repositories. http://dare.uva.nl/document/150723 (accessed 9 March 2012).
Notes
1.http://www.bbaw.de/en/ (accessed 9 March 2012).
2.http://www.bbaw.de/en/telota (accessed 9 March 2012).
3.http://www.dfg.de/en/ (accessed 9 March 2012).
4.http://www.europeana.eu/portal/ (accessed 9 March 2012).
5.http://www.deutsche-digitale-bibliothek.de/ (accessed 9 March 2012).
6.http://www.dariah.eu/ (accessed 9 March 2012).
7.http://www.clarin.eu/ (accessed 9 March 2012). (accessed 9 March 2012).
8.http://www.loc.gov/standards/mods/ (accessed 9 March 2012).
9.http://www.europeanaconnect.eu/news.php?area=News&pag=48 (accessed 9 March 2012).
10.http://www.w3.org/standards/semanticweb/data (accessed 9 March 2012).
11.http://www.deutschestextarchiv.de/ (accessed 9 March 2012).
12.http://www.dwds.de/ (accessed 9 March 2012).
13.http://www.mpiwg-berlin.mpg.de/en/ (accessed 9 March 2012).
14.http://archimedes.fas.harvard.edu/cgi-bin/donatus (accessed 9 March 2012).
15.http://www.w3.org/RDF/ (accessed 9 March 2012).
16.http://www.w3.org/TR/xhtml-rdfa-primer/ (accessed 9 March 2012).
17.http://lucene.apache.org/java/docs/index.html (accessed 9 March 2012).
18.http://lucene.apache.org/solr/ (accessed 9 March 2012).
19.http://www.microsofttranslator.com/tools/ (accessed 9 March 2012).
20.http://code.google.com/intl/de-DE/apis/language/translate/overview.html (accessed 9 March 2012).