
Clark, Ashley M., University of Illinois at Urbana-Champaign, USA, amclark4@illinois.edu Holloway, Steven W., University of Illinois at Urbana-Champaign, USA, hollowa2@illinois.edu
Summary
The humanities as a discipline has traditionally exhibited great care in documenting sources and establishing authentic chains of object transmission. Data provenance metadata, however, is rarely curated in digital humanities projects, perhaps due to the lack of interoperable standards for recording data provenance. Recent efforts by the W3C Provenance Working Group to create the PROV-DM (Provenance Data Model) and PROV-ASN (Provenance Abstract Syntax Notation) may answer the requirements of the e-humanist community for such a standard. We examine the provenance capture capabilities of two e-humanities virtual research environments (VRE), TextGrid and Meandre, which also serve as test-beds for PROV-ASN assertions. PROV-ASN provides an interlingua abstract enough to express a common set of data provenance assertions for both software environments. The data for these assertions must be culled manually from various directories and file-types in both TextGrid and Meandre. For data provenance metadata to become as normative a feature of the digital humanities as source provenance is for analog humanities, e-humanities developers need to aggregate provenance metadata, equip it with intuitive visualizations, and render it using interoperable standards capable of transcending a particular VRE or software platform.
Data Provenance and the Humanities
Like the source provenance of art and artifacts, ‘data provenance’ depends upon records to establish a chain of past events which provide context for a digital object at any point in time. However, data provenance traces not ownership changes to a static document, but transformations to a version of a dataset, which then produces further versions. Records of data provenance might then include information on authorship, the name and version of software used to produce transformations, and descriptions of the transformations themselves.
For over fifteen years, the legal, business, computer science, e-science, and e-humanities communities have developed data provenance requirements specific to their disciplines, yet they share a need for interoperable standards. To date, little published research in e-humanities explicitly focuses on data provenance. Paradoxically, humanities scholarship flourishes on traceable reference. Humanities researchers traditionally perform close readings of object relationships, which requires judgments of source trustworthiness, authority, conceptual derivation, and class membership. It is a matter of concern, then, that the humanities, with its native affinity for historical thinking, should find itself unable to migrate provenance documentation methods into the digital realm.
If data provenance is to benefit the humanities, e-humanists must provide coherent metadata about their computing environment, records of state transformation, and file forensics no different than those entailed for e-science validation. Those who view the datasets should also have access to complete provenance information, ideally in human-readable form aggregated as supplemental resources. For this to occur, e-humanities researchers need tools which can either generate such provenance information automatically, or make it easy to manually gather and output. Familiar commercial authoring tools, such as Microsoft Word and Adobe Photoshop, support actionable data provenance (rollbacks to earlier states via the ‘undo’ function), but provide at best meager data provenance in the guise of autonomous metadata, susceptible to extraction and persistent storage. Because they cannot capture data provenance at a high-enough level of abstraction, open-source metadata streams for digital cameras (EXIF) and Adobe software (XMP), useful as they are, cannot serve the e-humanists’ need for interoperable standards.
Provenance in e-Humanities Computing Environments
This poster will compare structured provenance metadata in two decidedly different e-humanities computing environments, TextGrid 1.0 and Meandre 1.4.9. By staging an identical literary ‘experiment,’ these tools illustrate typical provenance-capture shortfalls. This poster will also explore the advantages of machine-actionable, interoperable provenance metadata, using the W3C’s PROV-DM standard as a basis for examining the current bedlam of e-humanities data provenance silos.
Meandre
The extensible Meandre software framework is a Java-based, open-source semantic web authoring and publishing tool with heavy emphasis on linguistic annotation and text analytics. The tool is intended to promote rapid software prototyping within two graphical user interfaces, the Meandre Infrastructure and Workbench. Meandre was developed by the Automated Learning Group, National Center for Supercomputing Applications at Urbana-Champaign, as part of an Andrew W. Mellon Foundation-funded text-mining initiative sponsored by the Software Environment for the Advancement of Scholarly Research (SEASR).
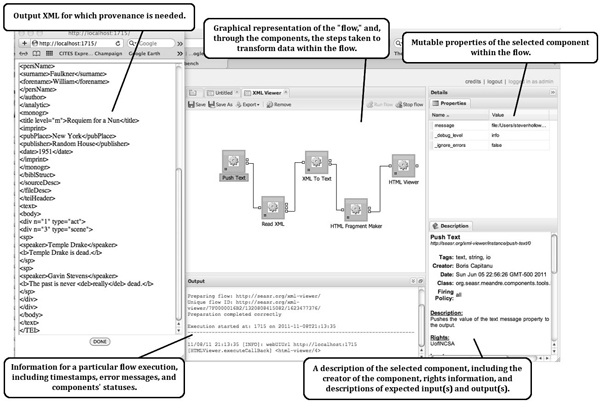 Figure 1: Provenance information as represented in Meandre
Figure 1: Provenance information as represented in Meandre
TextGrid
The Eclipse-based software TextGrid, funded by the Bundesministerium für Bildung und Forschung’s D-Grid initiative, represents an attempt to create an e-humanities VRE, consisting of both a ‘lab’ that runs on local hardware, and a sophisticated repository back-end fostering preservation, discovery and publication. A set of purpose-made tools facilitate Text Encoding Initiative (TEI) XML markup of documents and document-images in a collaborative environment. TextGrid was designed for scholars pursuing traditional philological studies, but is intended to serve musicologists, epigraphists, linguists, and art historians.
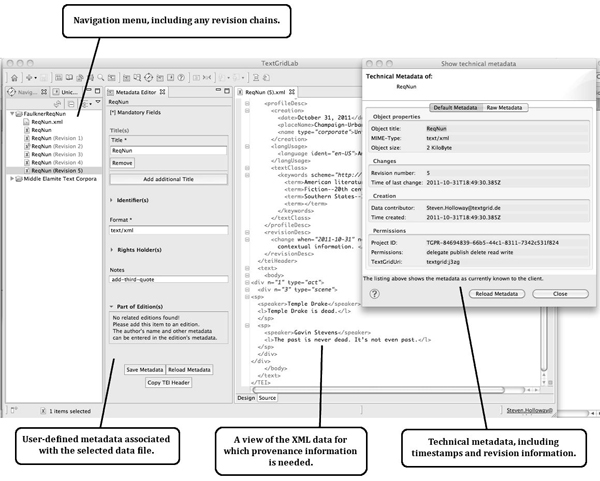 Figure 2: Provenance information as represented in TextGrid
Figure 2: Provenance information as represented in TextGrid
The W3C Provenance Data Model
Meandre and TextGrid serve as production work spaces, yet they fail to comprehensively log transformations of information in accessible ways. Though data provenance should be a requirement for e-humanities tools, solutions to provenance capture are a recent development. An emerging data provenance model, PROV-DM/-ASN, offers a means of capturing data provenance information at a level of abstraction that is hardware- and software-agnostic. For example, a passage from William Faulkner’s Requiem for a Nun edited in both TextGrid and Meandre could be expressed with the same PROV-ASN assertions, despite radically different processing architectures:
 Figure 3: Text transformations expressed through PROV-ASN assertions
Figure 3: Text transformations expressed through PROV-ASN assertions
In order to assemble comparable provenance metadata in TextGrid, it would be necessary, at a minimum, to manually open the five TEI revision files and view their descriptive and technical metadata in separate windows. A similar task in Meandre would require: saving five separate ‘workflows’ corresponding to the revisions e1-e5; viewing their associated documentation in both Workbench and Infrastructure; and manually accessing a variety of command-line log and server files.
The PROV-DM/-ASN specification makes allowances for recording system-specific details, such as software function names, component URIs, firing sequence, time of execution, and other technical metadata necessary for describing the process workflow. Since the PROV-O (Provenance Ontology) allows encoding in OWL2 web ontology language, the markup is machine-readable. In Meandre, assembling the data for the platform-specific provenance metadata would entail querying specific projects with command-line file utilities. Even then, some execution information would not persist after closing the program. In the TextGrid interface, a significant portion of execution information is simply unavailable. The experiment could be successfully re-run in Meandre and TextGrid using the saved workflow or project, respectively, but the full scope of the operating parameters remains concealed within software.
Concluding Remarks
Our poster shows that two prominent e-humanities VREs need considerable retooling to attain the benefits of comprehensive provenance metadata. Recent developments in provenance documentation standards promise the exchange of datasets with a common interlingua, facilitated descriptive analysis, and easier understanding of experimental protocols. Whether or not e-humanities developers adopt the PROV-DM/-ASN standard, the need for a systematic approach to data provenance-capture stands, as well as best practices which will benefit not only the users of e-humanities computing environments, but the larger digital humanities community.
Acknowledgments
This project was supported by DCEP-H, an initiative to extend the Data Curation Education Program to humanities. DCEP-H is based at the Center for Informatics Research in Science and Scholarship at and funded by IMLS Grant RE-05-08-0062-08.
References
Belhajjame, K., J. Cheney, D. Garijo, T. Lebo, S. Soiland-Reyes, and S. Zednik (2011). PROV Ontology Model, W3C Working Draft 13 December 2011. http://www.w3.org/TR/2011/WD-prov-o-20111213/ (accessed 9 March 2012).
Belhajjame, K., S. Cresswell, R. Golden, P. Groth, G. Klyne, J. McCusker, and S. Sahoo (2011). PROV Data Model and Abstract Syntax Notation, W3C Working Draft 18 October 2011. http://www.w3.org/TR/2011/WD-prov-dm-20111018/
Chao-fan, D., W. Tao, Z. Peng-cheng, and F. Yang-He (2010). A comparation of data provenance systems based on processing. IEEE International Conference on Intelligent Computing and Intelligent Systems 3: 374-379. Institute of Electrical and Electronics Engineers. http://dx.doi.org/10.1109/ICICISYS.2010.5658641
Freire, J., D. Koop, E. Santos, and C. T. Silva (2008). Provenance for computational tasks: A survey. Computing in Science & Engineering 10(3): 11-21. http://dx.doi.org/10.1109/MCSE.2008.79
Hasan, R., and M. Winslett (2009a). Trustworthy history and provenance for files and databases. Ph.D. thesis, University of Illinois at Urbana-Champaign. http://search.proquest.com/docview/304899850?accountid=14553 (accessed 9 March 2012).
Küster, M., C. Ludwig, Y. Al-Hajj, and T. Selig (2011). TextGrid provenance tools for digital humanities ecosystems. Proceedings of the 5th IEEE International Conference on Digital Ecosystems and Technologies 2011. Daejeon, Korea, pp. 317-323. http://dx.doi.org/10.1109/DEST.2011.5936615 (accessed 9 March 2012).
Neuroth, H., ed. (n.d.). TextGrid: Home. http://www.textgrid.de/en.html (accessed 9 March 2012).
Moreau, L. (2009). The foundations for provenance on the web. doi:10.1.1.155.784 (submitted)
Simmhan, Y. L., B. Plale, and D. Gannon (2005). A survey of data provenance in e-science. SIGMOD Record 34(3), 31-36.
Software Environment for the Advancement of Scholarly Research. (2011). Meandre. http://seasr.org/meandre (accessed 9 March 2012).