
In computational stylistics and authorship attribution recent work has usually concentrated on very frequent words, with a seemingly compelling logic: consistent and characteristic authorial habits seem most likely to exist among frequent function words not closely tied to plot, setting, and characterization, and not likely to be consciously manipulated. Analyses using frequent words have been very successful, and continue to be used (Craig & Kinney 2009). Some researchers have recently begun using many more words in analyses, often achieving excellent results by analyzing the 500-4,000 most frequent words (Hoover 2007). Yet even these words are not truly rare in a 200,000 word novel, where the 4,000th most frequent word typically has a frequency of 3-4.
Brian Vickers has recently attacked work based on common words, claiming that distinctive and unusual word Ngrams are better authorship markers than words for 16th century plays (Vickers 2008, 2009, 2011). He argues that rare Ngrams that are not found in a large reference corpus, but are found in one author’s corpus and in an anonymous text, strongly suggest common authorship. Vickers tests whether Thomas Kyd might have written the anonymous Arden of Faversham by searching for 3- to 6-grams shared by Arden and the three plays known to be by Kyd, but not found in a 64-play reference corpus of texts of similar genre and date. He finds more than 70. This method, an improved method of parallel hunting, is essentially an extreme version of Iota (Burrows 2007), but based on Ngrams rather than words. As he puts it, ‘One or two such close parallels might be dismissed as imitation, or plagiarism, but with over 70 identical word sequences, often quite banal phrases . . . that explanation falls away’ (Vickers 2008: 14). In a later article he reports 95 such matches between Arden and Kyd’s corpus (2009: 43). Does the existence of such rare matches constitute reliable evidence that Kyd wrote Arden? We can begin to answer this question by testing the method on texts of known authorship.
The texts Vickers works on are not ideal for testing: 16th century texts have substantial spelling variation, making automated methods problematic, the authorship and dates of individual plays in the period are often uncertain, and many of them involve collaboration. I instead test the method on American fiction ca 1900 and modern American poetry. Because Ngrams have been used increasingly in authorship study (Clement & Sharp 2003; Grieve 2007; Juola 2008), it seems useful to test frequent word Ngrams before looking at rare ones. My American fiction corpus consists of a bit more than 2 million words of third person narration (10,000-39,000 words each) extracted from 83 texts by 41 authors, 20 of the authors represented by one or more additional texts, 36 test texts in all. A cluster analysis of all 83 texts correctly groups all texts by 16 of the 20 authors; in three cases, one of an author’s texts fails to cluster with the others, and in the other case, the six texts by an author form two separate clusters. Delta correctly attributes 35 of the 36 possible texts in some analyses (on Delta, see Burrows 2002). Bigrams are less effective: a cluster analysis correctly groups only 14 of the 20 authors, and Delta correctly attributes a maximum of 32 of the 36 test texts. Trigrams are even less effective: cluster analysis is fairly chaotic, and Delta correctly attributes a maximum of 31 of the possible 36, with much weaker results overall. The same is true for American poetry, 2.7 million words of poetry by 29 authors, arranged in 23 primary composite samples (19,000-138,000 words), tested against 39 individual long poems (900-1,500 words). Word bigrams are much less effective than words and trigrams do a poor job. While word Ngrams have sometimes given better results than words alone, the results here do not support Vickers’s basic premise that Ngrams are inherently superior to words in characterizing an author’s style, even though they add syntactic information.
Rare Ngrams are a different matter, of course. In order to duplicate the scenario of Vickers’s tests on Kyd, I used 64 of the sections of third person narration above (by 23 authors) as a reference corpus. I collected a three-text corpus for James and eight other James texts as test texts. I also held out six other texts for further testing. There are about 6.5 million 3- to 6-grams in the entire corpus; because the method requires at least one match between texts, I first removed all hapax Ngrams and those found in only one text, leaving about 100,000. I then removed all those found in the reference corpus, leaving about 9,600. I took each of the eight James test texts in turn, and compared it with the James corpus, with the seven other James texts, and with the six texts by other authors, with respect to the proportion of Ngrams in each text that match those in the James corpus or the other texts. The results are shown in Figure 1.
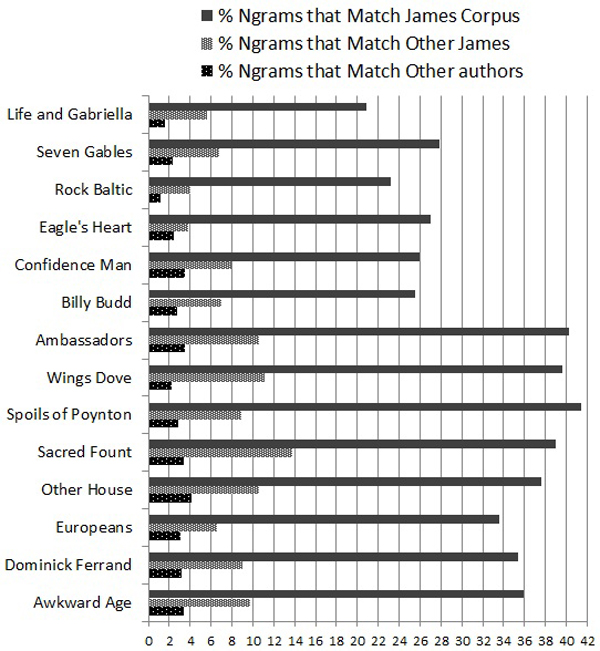
Figure 1: Rare Ngrams in James’s Fiction
It is clear that the Ngrams in the James test texts have a higher proportion of matches in the James corpus than do the texts by others, ranging from about 33% to 42%, while the other texts range from about 21% to 28%. But the difference between the James texts and the others is disturbingly small. Also disturbing is that two of the six other authors have more matches to other James texts than one of James’s own texts, and that all of the texts have about the same percentage of matches with texts by other authors. These facts are disturbing because Vickers bases authorship claims on the existence of ngrams found in an authorial corpus and an anonymous text that are not found elsewhere without doing the further tests above. Thus, if one were seriously testing The House of the Seven Gables for the possibility that Henry James wrote it, the fact that 28% (291) of the 1045 Ngrams found in Seven Gables have matches in the James Corpus but are found nowhere else in the reference corpus might seem like a strong argument. Remember that Vickers based an argument for Kyd’s authorship on only about 70 matches between the Kyd corpus and his three anonymous plays that were not found in the reference corpus (or 95 in his later article). (Why there are so many more here needs further investigation, but the somewhat greater average length of my samples is almost certainly a factor.) For the poetry corpus, things are even worse: Kees shows a higher proportion of matches to Rukeyser’s corpus than two sections of her own poetry, and Stafford is not far behind, as Fig. 2 shows.
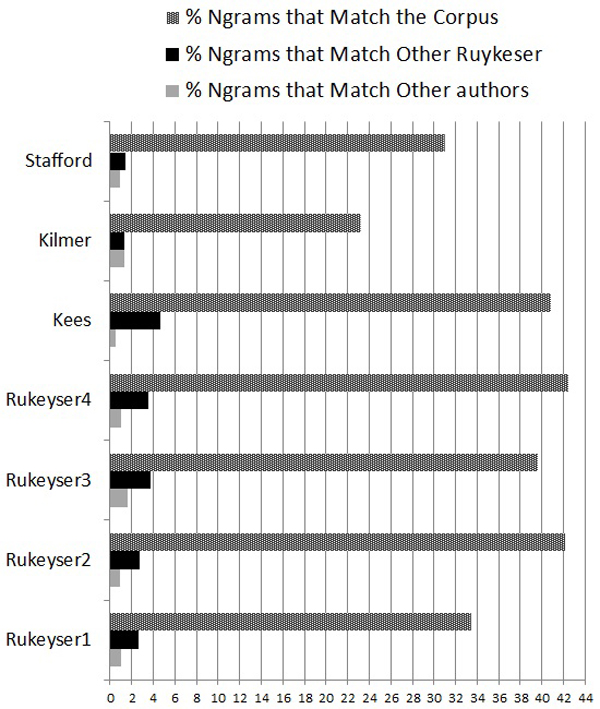
Figure 2: Rare Ngrams in Rukeyser’s Poetry
Finally, I tested a bogus composite author corpus consisting of the samples by Stafford, Kilmer, and Kees. As Fig. 3 shows, even with an unreal author, there are many Ngram matches between the bogus authorial corpus and each other text that are not found in the reference corpus. For many of the samples, 15% or more of their Ngrams match the bogus corpus but are not found anywhere else. If these texts were anonymous, it would be easy to repeat Vickers’s argument and claim that all of them must be by this illusory ‘author.’
Finally, preliminary tests in which additional texts are added to the analysis show that many of the matches between an authorial corpus and any given test text that are not found in the original reference corpus also have matches in one or more of the new texts. The results presented above suggest that rare Ngrams are unlikely to be good indicators of authorship, in spite of their initial plausibility. There are about 1.3 million trigrams in the 83 narrative texts discussed above, but only about 150,000 of them occur more than once, and the highest frequency is 853. In contrast, there are about 49,000 different words, about 30,000 of which occur more than once, and the highest frequency is 136,000. One might say simply, and somewhat paradoxically, that, although Vickers’s matching Ngrams are rare, there are so many of them that matches can be expected between almost any pair of texts, and some of these matches will also be absent from the reference corpus.
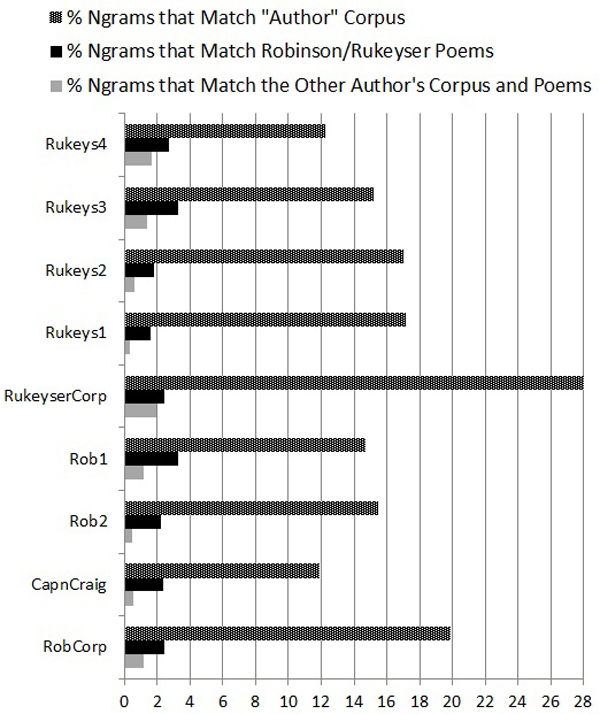
Figure 3: Rare Ngrams in a ‘Composite’ Author
References
Burrows, J. (2007). All the Way Through: Testing for Authorship in Different Frequency Strata. LLC 22: 27-47.
Burrows, J. (2002). ‘Delta’: A Measure of Stylistic Difference and a Guide to Likely Authorship. LLC 17: 267-87.
Clement, R., and D. Sharp (2003). Ngram and Bayesian Classification of Documents. LLC 18: 423-47.
Craig, H., and A. Kinney, eds. (2009). Shakespeare, Computers, and the Mystery of Authorship. Cambridge: Cambridge U. Press.
Grieve, J. (2007). Quantitative Authorship Attribution: An Evaluation of Techniques. LLC 22: 251-70.
Juola, P. (2008). Authorship Attribution. Foundations and Trends in Information Retrieval 1: 233-334.
Hoover, D. L. (2007). Corpus Stylistics, Stylometry, and the Styles of Henry James. Style 41: 174-203.
Vickers, B. (2011). Shakespeare and Authorship Studies in the Twenty-First Century. Shakespeare Quarterly 62: 106-42.
Vickers, B. (2009). The Marriage of Philology and Informatics. British Academy Review 14: 41-4.
Vickers, B. (2008). Thomas Kyd, Secret Sharer. Times Literary Supplement, 18 April 2008: 13–5.