
Introduction
The advent of revolutionary communication tools, like social media and image/video sharing, have transformed the Web into a giant collection of resources created by millions of people around the planet, representative of their different cultures and ideas. In this context, the Digital Humanities community have understood that Digital Libraries (DL) should no longer be simple ‘expositions’ of digital objects but rather provide interaction with users, enabling them to contribute with new knowledge, e.g. by annotating and tagging digital artefacts (Arko et al. 2006). This provides a more engaging user experience, enabling scholars to benefit from the digital world in their everyday work and researchers to work collaboratively (David et al. 2008). The crowdsourcing paradigm has been experimented, as in (Holley 2010), by leveraging users annotations to enrich the DL, helping in curating contents (correcting or signalling typos, etc.) or upload new digital material1.
Existing annotations tools, however, are often limited to context and tags, which provide poor semantics, and, when they offer more expressive annotations, use proprietary or non-interoperable formats to represent semantics. In other words, the knowledge created by advanced users carefully annotating contents with valuable information is often lost, since it is not directly reusable by applications.
In this paper we present the prototypal annotation system developed within the SemLib EU project. The SemLib Annotation System (AS) can be easily integrated into existing DL or used through a bookmarklet to annotate generic Web pages, addressing annotations at different level of complexity and expressivity. In the prototype, users can write simple comments, augment them with links to Linked Data2 (LOD) and semantic tags. But if they are scholars and need more expressivity they can create complex structured relations among digital objects, connecting text within different documents and relating to specific vocabulary terms.
Annotations are structured as RDF data, which is stored to a remote annotation server and can be consumed by third party applications as ‘slices’ of a single collaborative RDF graph.
The Role of Semantic Annotations
Data interoperability and reuse are the main achievements that the DL research community is trying to address by looking at Semantic Web (SW) and LOD technologies. As argued in previous researches (Kahan et al. 2001; Haslhofer 2010; Gerber et al. 2010) and witnessed by the Europeana initiative, which is adopting a RDF based data model (EDM), great expectations come for the semantic technologies. Semantically structured data is expected to provide the ability to mash-up heterogeneous information and establish connections among digital objects independently provided by different institutions.
Data interoperability and flexibility of aggregation foster reuse and enable serendipity: unexpected reuse of data by different persons and in different contexts from the one data was produced in. Users annotations, when properly represented as semantic data, can play an important role in this context, as they link documents to data.
On the one hand, semantic annotations represent precise relations and metadata and they are reusable with relatively low effort to augment the DL’s data. Here, it is very important to expose easily accessible APIs to ‘slice’ the RDF data produced. On the other hand, LOD annotations contain links to open datasets or ontologies that can be contextualized. This allows applications to merge annotations and augment their metadata with other semantic. As an example, if documents are connected to a world wide linked data graph, composed by big datasets, vocabularies and user annotations, software applications can let users explore such a graph and possibly discover unexpected and interesting connections among them.
Simple Use-Case
Let us shortly describe a simple use case that illustrates the kind of scenario that AS should address.
Alice is a researcher in politics and annotates a transcription of an election rally. She writes a comment to a passage and then clicks the ‘extract tags’ button. AS uses DBPedia Spotlight3 (or possibly other multi language entity extraction tools) to propose a set of entity tags, using remote metadata to build a preview with pictures, descriptions, etc. Alice chooses a number of tags including the politician ‘X’ who is mentioned in the transcription and then she loads an ‘emotions vocabulary’ that allows her to express a precise relation (e.g. ‘is a manifestation of’) between the annotated sentence and the term ‘rage’ from the vocabulary. Alices annotations are collected, among others by a virtual community of users, into a Web site exposing a RDF based faceted browser, where they are merged with further metadata about the DBPedia entities cited in annotations and ontologies.
A second user, Bob, made a similar annotation, semantically linking to the politician ‘Y’ from DBPedia. Since in DBpedia the two politicians are connected by their metadata (e.g. they are from the same party or they are born in the same city, etc.), the two entities can have one or more paths that connect them in the graph. Bob can explore such paths and discover a relation among his annotation and the one from Alice. In addition, when Bob search for the keyword ‘anger’, to find objects related to that emotion, he will be able to find the transcription annotated by Alice, since an emotion ontology is available and it defines ‘rage’ as a narrower term of ‘anger’. At this point, Bob could also decide to create a new semantic annotation expressing a similarity between the two transcriptions, for example, using a simple ‘is similar to’ relation.
Using the AS, DL administrators or DL owners/maintainers can make their own annotations but they can also select relevant end-user contributions, aggregate them and then publish back as trusted/official annotations, importing them to enrich the DL.
Annotations Data Model
Annotations represent a peculiar type of resources, specifically conceived to add information to other existing resources. Annotations acquire therefore full significance in relation with the target resource and other contextual information, such as its author, its creation date and the vocabulary terms used. Properly structuring an annotation using SW technologies is therefore necessary at twofold level to clearly separate contextual metadata from its content. The AS data model reuses and extends OAC ontology (Sanderson et al. 2011) to encode contextual metadata and to attach annotations to involved Web resources. Since OAC specification makes no assumption on the kind of body an annotation can have, one of the first issues that have been tackled in SemLib project is how to represent annotations that have an RDF graph as body. In AS data model, annotation body is a named graph containing a set of RDF statements. This allows to represent semantically structured annotation content basing on the standard support for named graphs provided by RDF triplestores and SPARQL in addition to query and access only little slices of the entire collaborative knowledge base (KB).
The annotation storage is agnostic with respect to the ontologies used to represent the informative content of annotations. Pluggable ontologies and SKOS taxonomies can be used to encode annotations content according to standardized domain vocabularies to foster data interoperability between different communities and DL.
Annotations Sharing Model
In AS users collect their annotations in notebooks to organize their work, aggregating annotations by topic or task, and to easily make available to others subsets of their annotations enabling collaborative scenarios. Notebooks are identified by dereferenciable URLs that applications can use to retrieve RDF-encoded annotations and relative metadata in different formats.
Sharing a notebook is as easy as sharing its URL on the Web, similarly to what happens for popular file sharing platforms and common mechanisms like e-mails, wikis or social networks can be used. For each notebook, the owner can easily set fine-grained rights access, also making it public or sharing it only with selected users.
Before creating and sharing annotations each user must signing into the annotation system. To make as easy as possible the integration of the annotation system in existing DL, single sign-on systems like OpenID and OAuth have been used. Different authentication systems can be supported developing dedicated plugins.
Prototype
At the time of writing, a fully working AS prototype4 has been developed and will be further enhanced in the continuation of the project. The prototype can be used in any existing Websites through a dedicated bookmarklet, which will injects the needed Javascript code into the Web pages.
System architecture, shown in Fig. 1, is typically client-server. The client-side component, which comprises a set of modules implementing the graphical user interface to create and browse annotations, is developed in Javascript. The server-side component is a RESTful Web service which implements the main application logic and the storage for the annotations based on a native Sesame triplestore with the support for semantic inference.
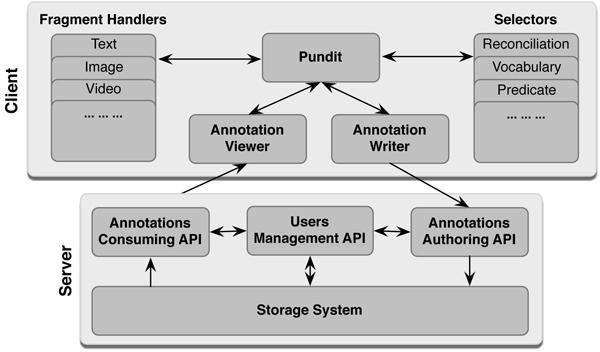
Figure 1: Simplified architecture of the Annotation System
The AS prototype allows users to compose RDF statements using an on purpose GUI (Fig. 2), connecting selected items with properties coming from pluggable ontologies.
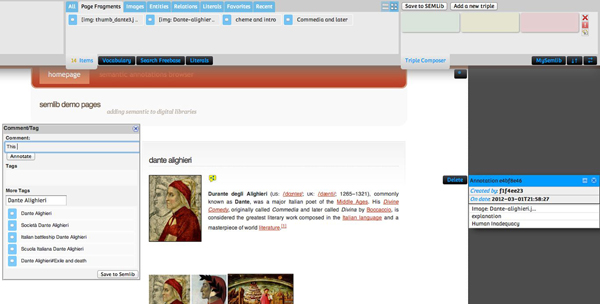
Figure 2: An example of the annotations editor
Selected items can be DL resources, named entities coming from custom SKOS vocabularies or Web reconciliation services like Freebase5 Web pages or fragments of these. For example, users can create structured annotations in Dante Alighieri’s DL page to reference other pages of the DL about Italian writers that have been influential for him, to provide additional information about his place of birth referring to Florence entity in Freebase or to link text-excerpts of the Divine Comedy coming from the Gutenberg Project6.
The AS prototype includes a module for comments and tags. At the moment, it provides basic functionalities including entity extraction from user comments (based on DBPedia Spotlight) and semantic tagging.
To demonstrate how annotation can be consumed basing on simple REST API, the AS prototype provides also an example faceted browsing facility, implemented using Simile Exhibit7.
Conclusions
In this work, SemLib annotation system have been introduced, discussing its data and annotation model and presenting a working annotation system prototype, discussing how this is expected not only to foster annotation sharing between DL and user engagement but also to allow the application of crowdsourcing paradigm in the creation of added value for the DL.
Fundings
The research leading to these results has received funding from the European Union’s Seventh Framework Programme managed by REA-Research Executive Agency [SEMLIB - 262301 - FP7/2007-2013 - FP7/2007-2011 - SME-2010-1].
References
Arko, R. A., K. M. Ginger, K. A. Kastens, and J. Weatherley (2006). Using annotations to add value to a digital library for education Online: http://www.dlib.org/dlib/may06/arko/05arko.html (accessed on 7th March 2012).
David, S., M. Nucci, and F. Piazza (2008). Talia: a Research and Publishing Environment for Philosophy Scholars. Proceedings of the Digital Humanities 2008 Conference, Oulu, Finland, 25th-29th June, 2008.
Gerber, A., and J. Hunter (2010). Authoring, Editing and Visualizing Compound Objects for Literary Scholarship. Journal of Digital Information 11.
Haslhofer, B., E. Momeni, M. Gay, and R. Simon (2010). Augmenting Europeana Content with Linked Data Resources. Proceedings of the 6th International Conference on Semantic Systems (I-Semantics), September 2010.
Holley, R. (2010). Crowdsourcing: How and Why Should Libraries Do It? D-Lib Magazine, The Magazine of Digital Library Research, March/April 2010.
Kahan, J., and M. R. Koivunen (2001). Annotea: An Open RDF Infrastructure for Shared Web Annotations. Proceedings of the 10th international conference on World Wide Web, pp. 623-632.
Morbidoni, C., M. Grassi, and M. Nucci (2011). Introducing SemLib Project: Semantic Web Tools for Digital Libraries. Proceedings of the International Workshop on Semantic Digital Archives – sustainable long-term curation perspectives of Cultural Heritage held as part of the 15th International Conference on Theory and Practice of Digital Libraries (TPDL), Berlin, 29th September 2011.
Sanderson, R., and H. van de Sompel (2011). Open Annotation: Beta Data Model Guide, Online: http://www.openannotation.org/spec/beta/ (accessed on 7th March 2012).
Notes
1.BBC WW2 People’s War: http://www.bbc.co.uk/ww2peopleswar/
2.Linked Data: http://linkeddata.org/
3.DBPedia Spotlight: http://dbpedia.org/spotlight
4.For for a working demo see http://metasound.dibet.univpm.it/release_bot/release/semlib-client_0.61-demo_page/examples/demo.html
5.Freebase: http://www.freebase.com/
6.Gutenberg Project: Gutenberg Project: http://www.gutenberg.org/