
authors & presenters
Bol, Peter Kees, Harvard University, USA, pkbol@fas.harvard.edu Hsiang, Jieh, National Taiwan University, Taiwan, jieh.hsiang@gmail.com Fong, Grace, McGill University, Canada, grace.fong@mcgill.caIntroduction
Overview
Digital content and tools for Chinese studies have been developing very quickly. The largest digital text corpus currently has 400 million characters. There is now an historical GIS for administrative units and towns in China from 221 BCE to 1911. And there are general and specialized biographical and literary databases. This wealth of resources is constrained, however, by the histories of their development: all have been developed independently of each other and there has been no systematic effort to create interoperability between them. This panel brings together three innovators in Chinese digital humanities and shows how, by implementing system interoperability and content sharing, their separate approaches to content and tool development can be mutually supporting and result in more powerful applications for the study of China’s history and literature. The goal of this session is both to introduce the projects the presenters lead and to demonstrate the advantages of sharing and interoperability across systems. Moreover, because their outputs are multi-lingual (Chinese, English translation, and pinyin) they are making the data from China’s past accessible to a non-Chinese-reading public.
The China Biographical Database (CBDB) has been accumulating biographical data on historical figures, mainly from the 7th through early 20th century. It populates the database by applying text-mining procedures to large bodies of digital texts. Users can query the system in terms of place, time, office, social associations and kinship, and export the results for further analysis with GIS, social networks, and statistical software. The Research Center for the Digital Humanities at National Taiwan University developed the Taiwan History Digital Library, a system for the spatial and temporal visualization of the distribution of Taiwan historical land deeds, creating a temporally-enabled map interface that allows users to discover relevant documents, examine them and track their frequency. Using CBDB code tables of person names, place names, and official titles for text mark-up, the Center is now applying this system to a compendium of 80,000 documents from the 10th through early 13th century that cover all aspects of government, including such diverse topics as religious activity, tax revenues and bureaucratic appointments. Users will be able to track the careers of individuals and call up their CBDB biographies through time and space as well as seeing when, where, and what the government was doing. This will be a model for incorporating the still larger compendia of government documents from later periods. Data will be discovered (e.g. the location and date of official appointments) and deposited into the CBDB. The Ming Qing Women’s Writings (MQWW) project is a multilingual online database of 5000 women writers from Chinese history which includes scans of hitherto unavailable works and analyses of their content. Users can query the database by both person and literary content. Using APIs to create system interoperability between MQWW and CBDB, MQWW is building into its interface the ability to call up CBDB data on kinship, associations, and careers of the persons in MQWW. For their part CBDB users will be able to discover the writings of women through the CBDB interface.
Chinese Biographical Data: Text-mining, Databases and System Interoperability
Biography has been a major component of Chinese historiography since the first century BCE and takes up over half the contents in the twenty-five dynastic histories; biographical and prosopographical data also dominate the 8500 extant local histories. The China Biographical Database is a collaborative project of Harvard University, Peking University, and Academia Sinica to collect biographical data on men and women in China’s history (Bol and Ge 2002-10). It currently holds data on about 130,000 people, mainly from the seventh through early twentieth century, and is freely available as a downloadable stand-alone relational database, as an online manual inputting system, and as an online query system with both />English and >Chinese interfaces. Code and data tables cover the multiple kinds of names associated with individuals, the places with which they were associated at birth and death and during their careers, the offices they held, the educational and religious institutions with which they were associated, the ways in which they entered their careers (with special attention to the civil service examination), the people they were associated with through kinship and through non-kin social associations (e.g. teacher-student), social distinction, ethnicity, and writings (Fuller 2011).
The purpose of the database is to enable users, working in Chinese or English, to use large quantities of prosopographical data to explore historical questions (Stone 1972). These may be straightforward (e.g. What was the spatial distribution of books by bibliographic class during a certain period? How did age at death vary by time, space, and gender?) or complex (e.g. What percentage of civil officials from a certain place during a certain period were related to each other through blood or marriage? How did intellectual movements spread over time?). The standalone database and the online query system also include routines for generating genealogies of any extent and social networks of up to five nodes, finding incumbents in a particular office, etc. The standalone database (and next year the online system) can also output queries in formats that can be analyzed with geographic information system and social network analysis software (Bol 2012). Historical social network analysis is challenging but rewarding (Padgett & Ansell 1993; Wetherhall 1998).
We began to populate the database largely through text-mining and text-modeling procedures. We began with Named Entity Recognition procedures (e.g. finding text-strings that matched reign periods titles, numbers, years, months, and days to capture dates, with 99% recall and precision) written in Python. We then proceeded to write more complex Regular Expressions to identify, for example, the office a person assumed at a certain date, where the office title is unknown. Currently we are implementing probabilistic procedures to identify the social relationship between the biographical subject and the names of people co-occurring in the biographical text (we have reached a 60% match with the training data).
An important outcome for the humanities generally is Elif Yamangil’s (Harvard University: Computer Science) development of the ‘Regular Expression Machine.’ This is a graphical user interface (GUI) built within Java Swing library that allows a user to graphically design patterns for biographical texts, match these against the data and see results immediately via a user-friendly color-coding scheme. It consists of a workspace of three main components: (1) a view that displays the textual data currently used, (2) a list of active regular expressions that are matched against the data via color-coding, and (3) a list of shortcut regular expression parts that can be used as building-blocks in active regular expressions from (2). Additional facilities we have built into our product are (1) an XML export ability: Users can create XML files that flatten the current workspace (data and regular expression matched against) at the click of a button. This facilitates interfacing to other programs such as Microsoft Excel and Access for database input. (2) A save/load ability: Users can easily save/load the workspace state which includes the list of regular expressions and shortcuts and their color settings. (3) A handy list of pre-made regular expression examples: Numerous date patterns can be added instantly to any regular expression using the GUI menus. The point of building this application is to allow users with no prior experience with programming or computer science concepts such as regular expression scripting to experiment with data-mining Chinese biographical texts at an intuitive template-matching understanding level only, yet still effectively.
The CBDB project also accepts volunteered data. Our goal in this is social rather than technical. Researchers in Chinese studies have long paid attention to biography and in the course of their research have created tables, and occasionally databases, with biographical data. By offering standard formats and look-ups and queries for coding, we provide researchers with a permanent home for their data. Currently there are twelve collaborating research projects, among which are an extensive database of Buddhist monks, a collection of 5000 grave biographies, 30,000 individuals active in the ninth through tenth centuries. The more biographical data the project accumulates the greater the service to research and learning that explore the lives of individuals.
Humanists are exploring ways in which they can use data in quantity and looking for ways of making it accessible to others on the web. In Chinese studies – speaking now only of those online systems that include biographical data – these include the Tang Knowledge Database at the Center for Humanistic Research at Kyoto University, the Ming-Qing Archives at Academia Sinica and the National Palace Museum Taiwan, the databases for Buddhist Studies at Dharma Drum College, Ming Qing Women’s Writings Database at McGill University, and the University of Leuven’s database of writings by Christian missionaries and converts in China. The role of the China Biographical Database project in this environment is to provide an online resource for biographical data that others can draw on to populate fields in their own online systems. To this end we are currently developing (and will demonstrate this summer) a set of open Application Programming Interfaces that will allow other systems to incorporate data from the China Biographical Database on the fly. This will allow other projects to focus their resources on the issues that are of most interest to them while at the same time being able to incorporate any or all the data in CBDB within their own systems.
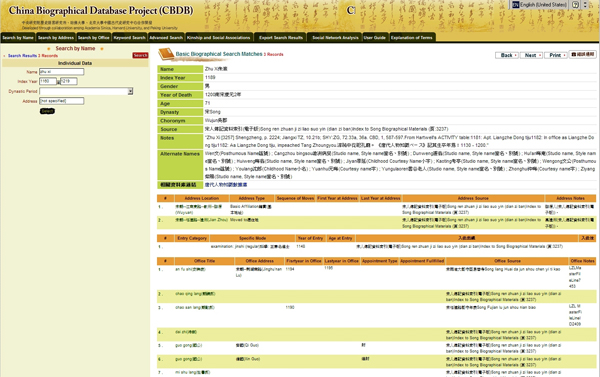
Figure 1: Online search results for Zhu Xi
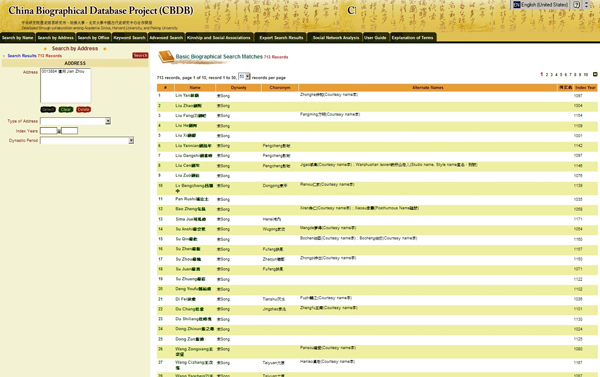
Figure 2: Persons in CBDB from Jianzhou in the Song period
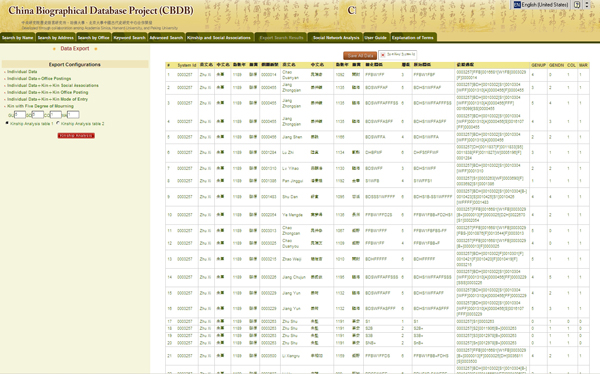
Figure 3: Kin to Zhu Xi (5 generations up and down, collateral and marriage distance of 1)
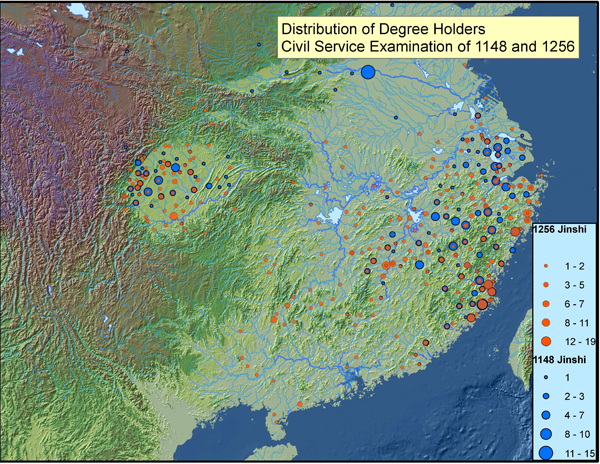
Figure 4: Civil Service Examination degree holders of 1148 and 1256
References
Bol, P. K. (2007). Creating a GIS for the History of China. In A. Kelly Knowles and A. Hillier (eds.), Placing History: How Maps, Spatial Data, and GIS Are Changing Historical Scholarship. Redlands, CA: ESRI Press, pp. 25-57.
Bol, P. K. (2012). GIS, Prosopography, and History. Annals of GIS 18(1): 3-15.
Bol, P. K., and Ge Jianxiong 葛剑雄 (2002-10). China historical GIS [electronic resource] = Zhongguo li shi di li xin xi xi = 中国历史地理信息系统. Version 1.0-5.0 Harvard University and Fudan University.
Fuller, M. A. (2011). CBDB User’s Guide. 2nd edition. Harvard University: China Biographical Database.
Padgett, J. F., and Chr. K. Ansell (1993). Robust Action and the Rise of the Medici, 1400-1434. American Journal of Sociology 98: 1259-319.
Stone, L. (1972). Prosopography. In F. Gilbert, E. J. Hobsbawm and St. Richards Graubard (eds.), Historical studies today., xxi, 469. New York: Norton.
Wetherhall, Ch. (1998). Historical Social Network Analysis. In L. J. Griffin and M. van der Linden (eds.), New methods for social history. Cambridge, New York: Cambridge UP, p. 165.
Context discovery in historical documents – a case study with Taiwan History Digital Library (THDL)
Research on pre-1900 Taiwanese history has suffered from the lack of primary historical documents. Most of the local government records, except for the Danxin Archives (an archive of about 20,000 official documents from the two northern Taiwan prefectures during the 19th century) are lost. Although there are quite a few records about Taiwan in the Imperial Court archives, they are kept in several different institutions, scattered among the volumes, and are hard to access. The situation with local documents such as land deeds is even worse. Some are published in local gazetteers or books, and some are family records kept by individual researchers for their own research use. There was an urgent need to collect primary documents and put them under one roof so that they can be better utilized by scholars.
In 2002 the Council of Cultural Affairs of Taiwan commissioned the National Taiwan University Library to select imperial court documents relevant to Taiwan from the Ming and Qing court archives, and the National Taichung Library to collect local deeds (especially land deeds). More than 30,000 court documents and 19,000 local deeds were collected and transcribed into full text. Most of the court documents and a portion of the land deeds were then published, from 2003 to 2007, into a book series of 147 volumes.
At the same time, CCA authorized the Research Center for Digital Humanities (RCDH) of NTU to create a digital library so that the digital files of the found materials could be used on line. In addition to creating THDL, the Taiwan History Digital Library, RCDH also added a significant number of documents that were collected later. THDL now contains three corpuses, all in searchable full-text. The Ming and Qing Taiwan-related Court Document Collection, numbered at 45,722, are collected from about 300 different sources and includes memorials, imperial edicts, excerpts from personal journals of local officials, and local gazetteers. The Old Land Deeds Collection contains 36,535 pre-1910 deeds from over 100 sources, with new material added every month. The Danxin Archives includes about 1,151 government court cases with 19,557 documents. Together they form the largest collection of its kind, with over 100,000 documents, all with metadata and searchable full text. The three corpuses reflect 18th and 19th century Taiwan from the views of the central government, the local government, and grassroots respectively. THDL has been available for free over the Internet since 2009, and has already made an impact on research of Taiwanese history.
When designing THDL we encountered a challenge. Unlike conventional archives whose documents have a clear organization, the contents in THDL, being from many different sources, do not have predefined contexts. Although one can easily create a search-engine-like system that returns documents when given a query, such a system is cumbersome since the user has to peruse the returned documents to find the relevant ones. In THDL we use a different approach. We assume that documents may be related, and treat a query return (or any subset of documents) as a sub-collection – a group of related documents (Hsiang et al. 2009). Thus in addition to returning a list of documents as the query result, the system also provides the user with as many contexts about the returned sub-collection as possible. This is done in a number of ways. The first one is to classify the query return according to attributes such as year, source, type, location, etc. Visualization tools are provided to give the user a bird’s eyes view of the distributions. Analyses of co-occurrences of names, locations and objects provide more ways to observe and explore the relationships among the actors and the collective meanings of the documents. For example, co-occurrence analysis of terms reveals the names of the associates mentioned most often in the memorials from a certain official, or the most frequently mentioned names during a historical event. Figure 1 is a snapshot of THDL after issuing the query ‘找洗字’. The map on the left shows the geographic locations of the documents in the query return. The top is a chronological distribution chart, and the left column is the post-classification of the query result according to year. We have also developed GIS techniques both for issuing a query and for analyzing/visualizing query results. For the land deeds, for instance, one can draw a polygon to query about all the land deeds appeared in that region (Ou 2011). (Such a query is quite impossible using keywords.) Figure 2 contains such an example. In order to go beyond syntactic queries, we further developed text mining techniques to explore the citation relations among the memorials and imperial edicts of the Ming Qing collection (Hsiang et al. 2012), and land transaction relations among the deeds in the land deed collection (Chen et al. 2011). Both projects have produced transitivity graphs that capture historical phenomena that would be difficult to discover manually.
In order to accomplish the above we developed a number of text-mining techniques. Term extraction methods were developed to extract more than 90,000 name entities from the corpuses (Hsieh 2011), and information such as the locations, dates, the four reaches of the land deeds, prices, and patterns. Matching algorithms were designed to find the transaction, citation and other relations mentioned above (Huang 2009; Chen 2011). GIS-related spatial-temporal techniques have also been developed (Ou 2011).
The contents of the China Biographical Database (CBDB) and Ming Qing Women’s Writers (MQWW) described in other parts of this panel share a number of commonalities with the contents of THDL. In additional to being written in classical Chinese, the documents in each of the corpuses were collected from many different sources and spanned over hundreds of years. Furthermore, there are no intrinsic relations among the documents other than the obvious. To use such loosely knitted collections effectively in research would require a system that can help the user explore contexts that may be hidden among the documents. This is exactly what THDL provides. The designing philosophy of treating a query return as a sub-collection and the mining and presentation technologies developed for THDL can be adapted in the other two collections as well. Indeed, THDL’s design, interface, and mining technologies are flexible enough to easily incorporate other Chinese language corpuses. The only assumption is that the documents in a collection should have well-structured metadata, which is important for the purpose of post-classification of a sub-collection. If the full-text of the content is also available, then more sophisticated analytical methods such as co-occurrence analysis can be deployed.
We have worked with the CBDB team of Harvard and built, within a month, a fully functional system from the THDL shell for Song huiyao (宋會要), a compendium of government records between 10th and 13th century China. (The content was jointly developed at Harvard and the Academia Sinica of Taiwan.) The system has also incorporated 9,470 person names, 2,420 locations, and 3,366 official titles from CBDB and used them in co-occurrence analysis, classifications and other features. It also extracted, automatically, 11,901 additional terms from the corpus. To reduce the number of errors unavoidable from this automated process, we have designed a crowd-sourcing mechanism for users to make corrections and to add new terms they discovered when using the system. The new names obtained through this process will in turn be fed back to CBDB.
We have also built a prototype for MQWW with post-classification features. Significant enhancement to this system is being planned once we receive enough users’ feedback. Incorporating the names and locations of CBDB into the system is also being studied.
While the text mining techniques that we have described here are designed for the Chinese language, the retrieval methodology of treating a query return as a sub-collection and the mechanisms for discovering and representing its collective meanings is universal. It provides a way to present and analyze the query return that seems better suitable for scholars to explore digital archives than the more conventional search engine that treats a query return as a ranked list.

Figure 1: Snapshot of THDL with query term “找洗字”
 Figure 2: Query resulted from issuing a polygon (region) as a query
Figure 2: Query resulted from issuing a polygon (region) as a query
References
Chen S. P. (2011). Information technology for historical document analysis, Ph.D. thesis, National Taiwan University, Taipei, Taiwan.
Chen, S. P., Y. M. Huang, H. L. Ho, P. Y. Chen, and J. Hsiang (2011). Discovering land transaction relations from land deeds of Taiwan. Digital Humanities 2011 Conference, June 19-22, 2011. Stanford, CA, pp. 106-110.
Hsiang, J., S. P. Chen, and H. C. Tu (2009). On building a full-text digital library of land deeds of Taiwan. Digital Humanities 2009 Conference. Maryland, June 22-25, 2009, pp. 85-90.
Hsiang, J., S. P. Chen, H. L. Ho, and H. C. Tu (2012). Discovering relations from imperial court documents of Qing China. International Journal of Humanities and Arts Computing 6: 22-41.
Hsieh, Y. P. (2012), Appositional Term Clip: a subject-oriented appositional term extraction algorithm. In J. Hsiang (ed.), New Eyes for Discovery: Foundations and Imaginations of Digital Humanities. Taipei: National Taiwan UP, pp. 133-164.
Huang, Y. M. (2009). On reconstructing relationships among Taiwanese land deeds. MS Thesis, National Taiwan University, Taipei, Taiwan.
Ou, C.-H. (2011). Creating a GIS for the history of Taiwan – a case study of Taiwan during the Japanese occupation era. MS Thesis, National Taiwan University, Taipei, Taiwan.
System Interoperability and Modeling Women Writers’ Life Histories of Late Imperial China
Recent scholarship has shown that Chinese women’s literary culture began to flourish on an unprecedented level alongside the boom in printing industry in the late sixteenth century, and continued as a cultural phenomenon in the late imperial period until the end of the Qing dynasty (1644-1911) (Ko 1994; Mann 1997; Fong 2008; Fong & Widmer 2010). Over 4,000 collections of poetry and other writings by individual women were recorded for this period (Hu and Zhang 2008). These collections with their rich autobiographical and social contents open up gendered perspectives on and complicated many aspects of Chinese culture and society – unsuspected kinship and family dynamics, startling subject positions, new topoi and genres, all delivered from the experience of literate women. Yet, within the Confucian gender regime, women were a subordinated group and ideally to be located within the domestic sphere, and in many instances their writings had not been deemed worthy of systematic preservation. Perhaps less than a quarter of recorded writings in individual collections have survived the ravages of history; many more fragments and selections are preserved in family collections, local gazetteers, and various kinds of anthologies. Works by individual women have been difficult to access for research, as they have mostly ended up in rare book archives in libraries in China.
Aimed at addressing the problem of accessibility, the Ming Qing Women’s Writings project (MQWW; http://digital.library.mcgill.ca/mingqing) is a unique digital archive and web-based database of historical Chinese women’s writing enhanced by a number of research tools. Launched in 2005, this collaborative project between McGill and Harvard University makes freely available the digitized images of Ming-Qing women’s texts held in the Harvard-Yenching Library, accompanied by the analyzed contents of each collection, which can be viewed online, and a wealth of literary, historical, and geographical data that can be searched (Fig. 1-4). However, MQWW is not a full-text database – we do not have the funding resources for that, but it is searchable based on an extensive set of metadata. In addition to identifying thematic categories, researchers can link between women based on exchange of their work and correspondence, obtain contextual information on family and friends, and note the ethnicity and marital status of the women writers, among other data fields. Each text within a collection is analyzed and identified according to author, title, genre and subgenre, whether it is a poem, a prose piece, or chapter of a verse novel. The MQWW digital archive contains more than 10,000 poems (majority by women) and also more than 10,000 prose pieces of varying lengths and genres (some by men), ranging from prefaces to epitaphs, and over 20,000 images of original texts. It clearly enables literary research; conferences, research papers, and doctoral dissertations have drawn on the resources provided, as well, the database has been serving as an important teaching resource in North America, China, Hong Kong, and Taiwan.
While the MQWW database contains basic information on 5,394 women poets and other writers, it was not originally designed with biographical research in mind. Yet, continuing research has pointed to how family and kinship, geographical location and regional culture, and social networks and literary communities are significant factors affecting the education, marriage, and general life course of women as writers (Mann 2007; Widmer 2006). The current phase of the collaborative project with the China Biographical Database (CBDB), Harvard University, will develop the biographical data of MQWW for large-scale prosopographical study (Keats-Rohan 2007). It is guided by the potential for taking digital humanities research in the China field to a new stage of development by focusing on system interoperability. By this we mean that online systems are built so as to enable interaction with other online systems through an Application Programming Interface (API), which must be developed in both directions. Our methodological strength is based on the two robust databases with demonstrated long-term sustainability and scholarly significance. An API is being created for CBDB to enable it to interact with MQWW and vice versa. MQWW will retain its separate identity as a knowledge site with its unique digital archive of texts and multifunction searchable database. System interoperability will support cross-database queries on an ad hoc basis by individual users. We are developing an integrated search interface to query both databases.
My paper will be an experiment based on a project in progress. With the massive biographical data available in CBDB, I will formulate and test queries for kinship and social network analysis for women writers in MQWW for a life history model, or a prosopographical study, of writing women in late imperial China. Some of the questions I will address are:
- Can we map historical changes statistically to test the ‘high tides’ of women’s writings (mid seventeenth century and late eighteenth century), which were arrived at through non-statistical observations?
- What graphs do the data yield for women’s social associations when mapped according to geographical regions, historical periods, and male kin success in the civil examination system, and other defined parameters?
- How do the official assignments of male kin affect groups of women in their life cycle roles: as daughter, wife, mother, mother-in-law, grandmother?
- What social patterns can emerge, such as local and translocal marriage and female friendship, through social network analysis with data in CBDB?
The rich data for male persons in CBDB can offer possibilities for mapping the life history of women writers: the circulation of their books, the physical ‘routes’ of movement in their lives, their temporal and geographical experiences, and their subtle role in the social and political domain, and disclose unsuspected lines of family and social networks, political alliances, literati associations, and women’s literary communities for further study and analysis. The experiments can show the probabilities and possibilities of the new system interoperability for identifying not only normative patterns, but also ‘outlier’ cases in marginal economic, geographical, and cultural regions, for which social, political, and historical explanations can be sought through more conventional humanities research.
 Figure 1: Search poems of mourning by the keyword = dao wang (悼亡) using the English interface
Figure 1: Search poems of mourning by the keyword = dao wang (悼亡) using the English interface
 Figure 2: Search results displaying poem titles with the keyword = dao wang (悼亡) with links to digitized text images
Figure 2: Search results displaying poem titles with the keyword = dao wang (悼亡) with links to digitized text images

Figure 3: Digitized texts of the first set of dao wang (悼亡) poems in the result list
 Figure 4: Search results for the woman poet Xi Peilan (1760-after 1829)
Figure 4: Search results for the woman poet Xi Peilan (1760-after 1829)
References
Fong, G. S. (2008). Herself an Author: Gender, Agency, and Writing in Late Imperial China. Honolulu: U of Hawaii P.
Fong, G. S., and E. Widmer, eds. (2010). The Inner Quarters and Beyond: Women Writers from Ming through Qing. Leiden: Brill.
Hu, W., and H. Zhang (2008). Lidai funü zhuzuokao (zengdingben) (Catalogue of women’s writings through the ages [with supplements]). Shanghai: Shanghai guji chubanshe.
Keats-Rohan, K. S. B., ed. (2007). Prosopography Approaches and Applications: A Handbook. Oxford: Unit for Prosopographical Research, Linacre College, University of Oxford.
Ko, D. (1994). Teachers of the Inner Chambers: Women and Culture in Seventeenth-Century China. Stanford: Stanford UP.
Mann, S. (1997). Precious Records: Women in China’s Long Eighteenth-Century. Berkeley, CA: U of California P.
Mann, S. (2007). The Talented Women of the Zhang Family. Berkeley, CA: U of California P.
Widmer, E. (2006). The Beauty and the Book: Women and Fiction in Nineteenth-Century China. Cambridge, MA: Harvard University Asia Center.