
Burrows, Toby Nicolas, University of Western Australia, Australia, toby.burrows@uwa.edu.au
Context
This paper looks at the design and architecture of the Humanities Networked Infrastructure (HuNI), a national ‘Virtual Laboratory’ which is being developed as part of the Australian government’s NeCTAR (National e-Research Collaboration Tools and Resources) programme. One of NeCTAR’s main goals is the development of up to ten discipline-based ‘Virtual Laboratories’. The aims of this programme are to integrate existing capabilities (tools, data and resources), support data-centred research workflows, and build virtual research communities to address existing well-defined research problems.
Beginning in May 2012, HuNI has been funded until the end of 2013. It is being developed by a consortium of thirteen institutions, led by Deakin University in Melbourne.
Design Framework
HuNI is specifically designed to cover the whole of the humanities (defined as the disciplines covered by the Australian Academy of the Humanities). It uses scientific e-Research consortia as its model: large-scale, multi-institutional, interdisciplinary groups with an e-Research framework covering the entire field of research.
This approach has a sound academic basis. It emphasizes the interdisciplinary and trans-disciplinary reach of the e-Research services and tools which are included in the ‘Virtual Laboratory’ environment – and its value to researchers across the full range of humanities disciplines.
HuNI aims to join together the various digital services and tools which have already been developed for specific humanities disciplines, both by collecting institutions (libraries, archives, museums and galleries) and by academic research groups. It builds on these services and strengthens them, rather than superseding them.
Data-Centred Workflows
The very concept of ‘data’ can be problematic for the humanities. Nevertheless, a distinctive type of humanities data can be identified, different from the quantitative and qualitative data of the social sciences. This ‘humanities data’ consists of the various annotations, tags, links, associations, ratings, reviews and comments produced during the humanities research process, together with the entities to which these annotations refer: concepts, persons, places and events.
It is important to draw a distinction between ‘data’ in this sense and primary source materials, particularly in digitized form (Borgman 2007: 215-217 fails to make this distinction). Primary materials – even in the form of digital objects – are sources of data, rather than data per se.
A data-centred virtual laboratory for the humanities needs to include services for identifying these semantic entities and their relationships (using the Linked Open Data technical framework), and for capturing and sharing the annotations and other scholarly outputs which refer to them. While the Linked Open Data framework is a relatively recent development, there are already a sufficient number of projects and services underway in Europe and North America which can serve as case studies to demonstrate clearly the viability and value of this approach (Bizer, Heath & Berners-Lee 2009).
Integration of Existing Capabilities
Many significant Australian collections of digital content relevant to humanities research already exist. Some of these are descriptions of physical objects (e.g., books, museum objects and art works) and entities (e.g., people and places), some are collections of digital objects, and others are a mixture of the two. In most cases, these collections were not connected with each other except to the extent that they could be searched by services like Google. Working effectively across such a disparate range of sources has been a major challenge for humanities researchers.
The production-level tools for working with these collections of digital content are relatively limited. Most tools are designed to work with a single service or a single type of content, such as the visualization tools developed by AusStage1, the user tagging developed by the Powerhouse Museum in Sydney2, and the Heurist software3 developed by the University of Sydney for archaeology. The LORE tool (for annotation and the construction of virtual collections) works mainly with AustLit4, though its federated search also covers some other content services.
To meet NeCTAR’s Virtual Laboratory criteria, content sources need to be integrated (or at least inter-linked), and tools need to be usable across as many sources and types of content as possible. It is neither practical nor desirable to merge content from multiple disciplines into a single enormous database, given the extensive variations in standards and approaches. Federated searching across many services, on the other hand, will not build the data-centred platform required to support the other functions of the Virtual Laboratory. The only feasible solution for data integration is to deploy a Linked Open Data environment on a national scale.
Architecture and Services
The project has defined a data-centred workflow for the humanities, with three main stages:
- Discovery (search and browse services);
- Analysis (annotation, collecting, visualization and mapping);
- Sharing (collaborating, publishing, citing and referencing).
For the Analysis and Sharing functions, a suite of existing Open Source tools developed in Australia are being used and adapted as part of the project. These include:
- LORE – developed by AustLit for annotation, federated searching, visualization, aggregation and sharing of compound digital objects (Gerber, Hyland & Hunter 2010);
- Visualization tools developed by AusStage (Bollen et al. 2009);
- OHRM5 – developed by the University of Melbourne to model entity relationships and publish information about collections into aggregated frameworks;
- Heurist and FieldHelper – developed by the University of Sydney to aggregate data, model entity relationships and publish collections of data to the Web (including maps and timelines).
The main adaptation required is to extend their functionality to work with Linked Data URIs and to be hospitable to cloud-based hosting. Where no Australian tool can be used or adapted, international Open Source tools will be used.
The annotations, compound objects and tags created by researchers using the Analysis tools will be stored in RDF as part of HuNI’s Linked Data Service. Descriptions of these data collections will also be made available for harvesting in RIF-CS format by the Australian National Data Service (ANDS) for its Research Data Australia service.
HuNI’s Discovery environment builds on the technologies used by a variety of Australian and international services to provide sophisticated searching and browsing across data extracted from heterogeneous data sets and combined into a Linked Data Service. These models include the Atlas of Living Australia6, as well as general humanities-related services like SOCH (Swedish Open Cultural Heritage) and discipline-specific services like CLAROS. The British Museum’s new ResearchSpace will also serve as a key exemplar.
The Discovery environment is underpinned by the Linked Data Service. The preferred solution for supporting and presenting Linked Data is the Vitro software developed by Cornell University, which serves as the basis for the VIVO research profiling service. VIVO has been implemented at two of the HuNI partner institutions: the University of Melbourne and the University of Western Australia.
The outputs from the Discovery environment will be produced in formats which can be consumed by tools performing Analysis and Sharing functions. The Linked Data Service will support an API for exposing data in RDF/XML and JSON formats. This API will form the basis for reuse of the data by service providers other than HuNI, as well as enabling the custodians of data sets which contribute to HuNI to build workflows for pulling new content from the Linked Data Store into their own data sets.
A necessary prerequisite for assembling heterogeneous data from different data sets into a Linked Data format is a Semantic Mediation and Mapping Service. There will be two main components to this service:
- Tools for extracting, exposing and transforming entity data contained in existing cultural data sets and in digital objects;
- An environment for harvesting, ingesting, matching, aligning, and linking the entity data.
For extracting and exposing entity data, two different approaches will be supported. The major content providers will develop and provide RESTful Web APIs for their data sets. A service will also be established to allow smaller data providers to expose their data for transformation and ingest without the need to develop an API. This service will use the harvest and ingest functionality of the Vitro software. Tools for converting static databases and spreadsheets to RDF will also be deployed. Data ingest from entity identification using text mining will follow at a later stage.
The Semantic Mediation and Mapping Service will draw on a range of vocabulary and identifier services, which will be managed through a controlled vocabulary registry with links to the ANDS identifier and vocabulary services. HuNI’s initial focus will be on matching, aligning and linking data relating to people, places and objects, using several high-level vocabularies and ontologies. These include Australian vocabularies like the Gazetteer of Australia7 and the PeopleAustralia service (Dewhurst 2008).
The HuNI service will enable researchers to find and analyse data across a range of humanities disciplines, and to save the outputs of their analysis in a variety of forms, including compound digital objects, annotations, maps, timelines, and graphs. They will be able to share their results and outputs with other researchers.
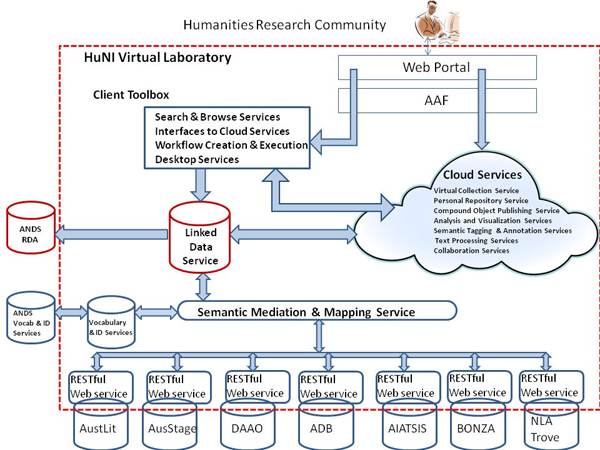 Figure 1: HuNI Architecture
Figure 1: HuNI ArchitectureReferences
Bizer, C., T. Heath, and T. Berners-Lee (2009). Linked Data – The Story So Far. International Journal on Semantic Web and Information Systems 5(3): 1-22.
Bollen, J., N. Harvey, J. Holledge, and G. McGillivray (2009). AusStage: e-Research in the Performing Arts. Australasian Drama Studies 54: 178-194.
Borgman, C. L. (2007). Scholarship in the Digital Age: Information, Infrastructure, and the Internet. Cambridge, Mass.: MIT Press.
Dewhurst, B. (2008). People Australia: a Topic-Based Approach to Resource Discovery. In VALA2008 Conference proceedings. Melbourne: VALA. http://www.valaconf.org.au/vala2008/papers2008/116_Dewhurst_Final.pdf (accessed 30 March 2012).
Gerber, A., A. Hyland, and J. Hunter (2010). A Collaborative Scholarly Annotation System for Dynamic Web Documents – A Literary Case Study. In The Role of Digital Libraries in a Time of Global Change (Lecture Notes in Computer Science 6102). Berlin: Springer, pp. 29-39.
Notes
1.AusStage is the Australian performing arts service (www.ausstage.edu.au)
4.AustLit is the Australian literature service (www.austlit.edu.au)