
authors & presenters
Nelson, Robert K., University of Richmond, USA, rnelson2@richmond.edu Mimno, David, Princeton University, USA, david.mimno@gmail.com Brown, Travis, University of Maryland, College Park, USA, travisrobertbrown@gmail.comIntroduction
The enormous digitized archives of books, journals, and newspapers produced during the past two decades present scholars with new opportunities – and new challenges as well. The possibility of analyzing increasingly large portions of the historical, literary, and cultural record is incredibly exciting, but it cannot be done with conventional methods that involve close reading or even not-so-close skimming. These huge new text archives challenge us to apply new methods. This panel will explore one such method: topic modeling.
Topic modeling is a probabilistic, statistical technique that uncovers themes and topics and can reveal patterns in otherwise unwieldy amounts of text. In topic modeling, a ‘topic’ is a probability distribution over words or, put more simply, a group of words that often co-occur with each other in the same documents. Generally these groups of words are semantically related and interpretable; in other words, a theme, issue, or genre can often be identified simply by examining the most common words in a topic. Beyond identifying these words, a topic model provides proportions of what topics appear in each document, providing quantitative data that can be used to locate documents on a particular topic or theme (or that combine multiple topics) and to produce a variety of revealing visualizations about the corpus as a whole.
This panel will, first and foremost, illustrate the interpretative potential of topic modeling for research in the humanities. Robert K. Nelson will analyze the similarities and differences between Confederate and Union nationalism and patriotism during the American Civil War using topic models of two historic newspapers. Travis Brown will explore techniques to tailor topic model generation using historical data external to a corpus to produce more nuanced topics directly relevant to particular research questions. David Mimno (chief maintainer of the most widely used topic modeling software, MALLET) will describe his work using topic modeling to generate – while respecting copyright – a new scholarly resource in the field of Classics that derives from and organizes a substantial amount of the twentieth-century scholarly literature.
The panel will also address methodological issues and demonstrate new applications of topic modeling, including the challenge of topic modeling across multi-lingual corpora, the integration of spatial analysis with topic modeling (revealing the constructedness of space, on the one hand, and the spatiality of culture, on the other), and the generation of visualizations using topic modeling useful for ‘distant reading.’ The panel thus addresses issues of multilingualism, spatial history, data mining, and humanistic research through computation.
Modeling Nationalism and Patriotism in Civil War America
Scholars of the American Civil War have productively attended to particular keywords in their analyses of the conflict’s causes and its participants’ motivations. Arguing that some words carried extraordinary political and cultural weight at that moment, they have sought to unpack the deep connotations of terms that are especially revealing and meaningful. To take a couple of recent examples, Elizabeth R. Varon frames Disunion!: The Coming of the American Civil War, 1789-1859 (unsurprisingly) around the term ‘disunion’: ‘This book argues that ‘disunion’ was once the most provocative and potent word in the political vocabulary of Americans’ (Varon 2008: 1). Similarly, in The Union War Gary W. Gallagher emphasize the importance of ‘Union,’ arguing that ‘No single word in our contemporary political vocabulary shoulders so much historical, political, and ideological meaning; none can stir deep emotional currents so easily’ (Gallagher 2011: 46). Others studies have used terms like ‘duty,’ ‘honor,’ ‘manliness,’ ‘freedom,’ ‘liberty,’ ‘nation,’ ‘republic,’ ‘civilization,’ ‘country,’ and ‘patriotism’ to analyze the ideological perspectives and cultural pressures that shaped the actions and perspectives of soldiers and civilians during the Civil War (Linderman 1987; Prior 2012; Gallagher 1997: 73).
Together, the production of enormous digital archives of Civil War-era documents in the past decade and the development of new sophisticated text-mining techniques present us with an opportunity to build upon the strengths of this approach while transcending some of its limitations. While unquestionably insightful, arguments that have relied heavily upon keyword analyses are open to a number of critiques. How do we know that the chosen keywords are the best window through which to examine the issues under investigation? How can we know – especially in studies which rely upon keyword searches in databases – that we have not missed significant evidence on the topic that does not happen to use the exact terms we look for and analyze? Does the selection of those words skew our evidence and predetermine what we discover? Topic modeling addresses these critiques of the keyword approach while offering us potentially even greater insights into the politics and culture of the era. First, as a ‘distant reading’ approach it is comprehensive, allowing us to analyze models that are drawn not from a selection but from the entirety of massive corpora. Second, as it identifies word distributions (i.e. ‘topics’), topic modeling encourages – even forces – us to examine larger groups of related words, and it surfaces resonant terms that we might not have expected. Finally and perhaps most importantly, the topics identified by this technique are all the more revealing because they are based on statistical relationships rather than a priori assumptions and preoccupations of a researcher.
This presentation will showcase research into Union and Confederate nationalism and patriotism that uses topic modeling to analyze the full runs of the Richmond Daily Dispatch and the New York Times during the war – taken together a corpus consisting of approximately 90 million words. It will make three interrelated arguments drawn from a combination of distant and close readings of topic models of the Dispatch and the Times.
First, I will argue that Confederates and Yankees used the same patriotic language to move men to be risk their lives by fighting for their countries. Distinct topic models for the Dispatch and the Times each contain topics with substantially overlapping terms (see table below) – terms saturated with patriotism. Typically celebratory of the sacrifices men made in battle, the patriotic pieces (often poems) in these similar topics from each paper aimed to accomplish the same thing: to evoke a love of country, God, home, and family necessary to move men to risk their lives and believe that it was glorious to die for their country.

Table 1: The top 24 predictive words for two topics from the Dispatch and the Times, with the words they shared in bold
Second, I will suggest that southerners (or at least the editor of the Dispatch) developed a particularly vitriolic version of Confederate nationalism to convince southern men to kill northerners. The Dispatch was full of articles that insisted that northerners were a foreign, unchristian, and uncivilized people wholly unlike southerners; in vicious editorials the Dispatch’s editor maintained that northerners were infidels and beasts who it was not only okay but righteous to kill. The remarkably similar signatures evident in a graph of two topics (Figure 1) – one consisting of patriotic poetry aimed at moving men to die, the other of vicious nationalistic editorials aimed at moving them to kill – from a model of the Dispatch suggests, first, the close relationship between these two topics and, second, the particular moments when these appeals needed to be made: during the secession crisis and the early months of the war in the spring and summer of 1861 when the army was being built, immediately following the implementation of the draft in April 1862, and at the end of the war in early 1865 as Confederates struggled to rally the cause as they faced imminent defeat.
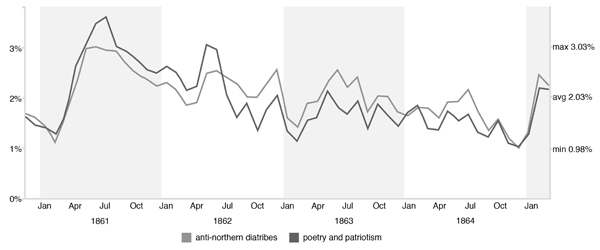
Figure 1
Finally, I will argue the kind of nationalism evident in the Dispatch was not and could not be used by northerners for the same purpose. While northerners and southerners used the same language of patriotism, there is no analog to the vicious nationalistic topic from the Dispatch in the topic model for the New York Times. Unionists insisted that the South was part of the United States and southerners had been and continued to be Americans – though traitorous Americans, to be sure. As a title of one article in the Times proclaimed, this was ‘Not a War against the South.’ It was a war against traitors, the Times insisted, and the ‘swords [of Union soldiers] would as readily seek a Northern heart that was false to the country as a Southern bosom’ (‘Not a War against the South,’ 1861). Northern nationalism is evident in the model for the Times in a more politically inflected topic on Unionism and a second topic consisting of patriotic articles and poems. The graphs of these two topics (Figure 2) with spikes during elections seasons suggest the instrumental purpose of nationalistic and patriotic rhetoric in the Times: not to draw men into the army but rather to drive them to the polls. The editor of the Times (correctly, I think) perceived not military defeat but flagging popular will as the greatest threat the Union war effort, and victory by copperhead Democrats who supported peace negotiations would have been the most potent expression of such a lack of will.
In briefly making these historical and historiographic arguments about nationalism and patriotism and about dying and killing in the American Civil War, this presentation aims to demonstrate the interpretative potential of topic modeling as a research methodology.
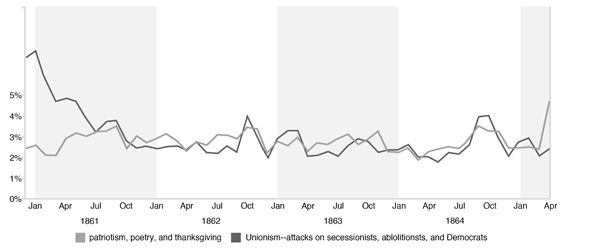
Figure 2
References
Gallagher, G. W. (1997). The Confederate War. Cambridge: Harvard UP.
Gallagher, G. W. (2011). The Union War. Cambridge: Harvard UP.
Linderman, G. F. (1997). Embattled Courage: The Experience of Combat in the American Civil War. New York: Free Press.
Not a War Against the South. (1861). New York Times. 10 May. Available at: http://www.nytimes.com/1861/05/10/news/not-a-war-against-the-south.html [Accessed on 13 March 2012].
Prior, D. (2010). Civilization, Republic, Nation: Contested Keywords, Northern Republicans, and the Forgotten Reconstruction of Mormon Utah. Civil War History 56(3): 283-310.
Varon, E. R (2008). Disunion!: The Coming of the American Civil War, 1789-1859. Chapel Hill: U of North Carolina P.
Telling New Stories about our Texts: Next Steps for Topic Modeling in the Humanities
Latent Dirichlet Allocation (LDA) topic modeling has quickly become one of the most prominent methods for text analysis in the humanities, with projects such as the work by Yang et al. (2011) on Texas newspapers and Robert Nelson’s Mining the Dispatch (Nelson 2010) demonstrating its value for characterizing large text collections. As an unsupervised machine learning technique, LDA topic modeling does not require manually annotated training corpora, which are often unavailable (and prohibitively expensive to produce) for specific literary or historical domains, and it has the additional benefit of handling transcription errors more robustly than many other natural language processing methods. The fact that it accepts unannotated (and possibly uncorrected) text as input makes it an ideal tool for exploring the massive text collections being digitized and made available by projects such as Google Books and the HathiTrust Digital Library.
LDA is an example of a generative model, and as such it has at its heart a ‘generative story,’ which is a hypothetical narrative about how observable data are generated given some non-observable parameters. In the LDA story, we begin with a set of topics, which are simply probability distributions over the vocabulary. The story then describes the process by which new documents are created using these topics. This process (which has been described many times in the topic modeling literature; see for example the original presentation by Blei et al. (2003)) is clearly not a realistic model of the way that humans compose documents, but when we apply LDA topic modeling to a set of documents we assume that it is a useful simplification. After making this assumption, we can essentially ‘play the story in reverse,’ using an inference technique such as Gibbs sampling to learn a set of topic distributions from our observed documents. Despite the simplicity of the generative story, the method can produce coherent, provocative, and sometimes uncannily ‘insightful’ characterizations of collections of documents.
While LDA topic modeling has a clear value for many applications, some researchers in the fields of information retrieval and natural language processing have described it as ‘something of a fad’ (Boyd-Graber 2011), and suggest that more attention should be paid to the broader context of generative and latent variable modeling. Despite the relatively widespread use of LDA as a technique for textual analysis in the humanities, there has been little work on extending the model in projects with a literary or historical focus. In this paper I argue that extending LDA – to incorporate non-textual sources of information, for example – can result in models that better support specific humanities research questions, and I discuss as examples two projects (both of which are joint work by the author and others) that add elements to the generative story specified by LDA in order to perform more directed analysis of nineteenth-century corpora.
The first of these projects extends LDA to incorporate geographical information in the form of a gazetteer that maps place names to geographical coordinates.1 We propose a region topic model that identifies topics with regions on the surface of the Earth, and constrains the generative story by requiring each toponym to be generated by a topic whose corresponding region contains a place with that name, according to the gazetteer. This approach provides a distribution over the vocabulary for each geographical region, and a distribution over the surface of the Earth for each word in the vocabulary. These distributions can support a wide range of text analysis tasks related to geography; we have used this system to perform toponym disambiguation on Walt Whitman’s Memoranda During the War and a collection of nineteenth-century American and British travel guides and narratives, for example.
The second project applies a supervised extension of LDA (Boyd-Graber & Resnik 2010) to a collection of Civil War-era newspapers.2 In this extension the model predicts an observed response variable associated with a document – in our case contemporaneous historical data such as casualty rates or consumer price index – on the basis of that document’s topics. We show that this approach can produce more coherent topics than standard LDA, and it also captures correlations between the topics discovered in the corpus and the historical data external to the corpus.
Both of these projects preserve the key advantages that the unsupervised nature of LDA topic modeling entails – the ability to operate on large, unstructured, and imperfectly transcribed text collections, for example – while adding elements of supervision that improve the generated topics and support additional kinds of analysis. While we believe that our results in these experiments are interesting in their own right, they are presented here primarily as examples of the value of tailoring topic modeling approaches to the available contextual data for a domain and to specific threads of scholarly investigation.
This work was supported in part by grants from the New York Community Trust and the Institute of Museum and Library Services.
References
Blei, D. M., A. Ng, and M. Jordan (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research 3: 993–1022.
Boyd-Graber, J. (2011). Frequently Asked Questions. http://www.umiacs.umd.edu/~jbg/static/faq.html (accessed 23 March 2012).
Boyd-Graber, J., and P. Resnik (2010). Holistic Sentiment Analysis Across Languages: Multilingual Supervised Latent Dirichlet Allocation. In Proceedings of Empirical Methods in Natural Language Processing. Cambridge, MA, October 2010.
Nelson, R. K. (2010). Mining the Dispatch. http://dsl.richmond.edu/dispatch/ (accessed 23 March 2012).
Speriosu, M., T. Brown, T. Moon, J. Baldridge, and K. Erk (2010). Connecting Language and Geography with Region-Topic Models. In Proceedings of the 1st Workshop on Computational Models of Spatial Language Interpretation. Portland, OR, August 2010.
Yang, T., A. Torget, and R. Mihalcea (2011). Topic Modeling on Historical Newspapers. In Proceedings of the 5th ACL-HLT Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. Portland, OR, June 2011. http://www.aclweb.org/anthology/W11-1513 (accessed 23 March 2012).
The Open Encyclopedia of Classical Sites: Non-consumptive Analysis from 20th Century Books
Traditional scholarship is limited by the quantity of text that a researcher can read. Advances in large-scale digitization and data analysis have enabled new paradigms, such as ‘distant reading’ (Moretti 2000). These data-driven approaches, though not approaching the subtlety of human readers, offer the ability to make arguments about entire intellectual fields, from collections spanning hundreds of years and thousands of volumes. Unfortunately, although such corpora exist, the current legal environment effectively prohibits direct access to material published after 1922, even for the great majority of works that are not commercially available (Boyle 2008). This paper explores the feasibility of scholarly analysis on the limited, indirect view of texts that Google Books can legally provide.
The proposed Google Books settlement (Google, Inc. 2011) presents the concept of ‘non-consumptive’ use, in which a researcher does not read or display ‘substantial portions of a Book to understand the intellectual content presented within the Book.’ The most common mode of access supported by archives such as JStor and Google Books is keyword search. When a user provides a query, the search engine ranks all documents by their relevance to a specific user-generated query and then displays short text ‘snippets’ showing query words in context. This interface, though useful, is not adequate for scholarship. Even if researchers have a specific query in mind, there is no guarantee that they are not missing related words that are also relevant. Word count histograms (Michel et al. 2011) suffer similar problems, and are also vulnerable to ambiguous words as they do not account for context.
Another option is the application of statistical latent variable models. A common example of such a method for text analysis is a statistical topic model (Blei, Ng Jordan 2003). Topic models represent documents as combinations of a discrete set of topics, or themes. Documents may be combinations of multiple topics; each topic consists of a probability distribution over words.
Statistical topic models have several advantages over query-based information retrieval systems. They organize entire collections into interpretable, contextually related topics.
Semantically related words are grouped together, reducing the chance of missing relevant documents. Instances of ambiguous words can be assigned to different topics in different documents, depending on the context of the document. For example, if the word ‘relief’ occurs in a document with words such as ‘sculpture’ or ‘frieze, ’ it is likely to be an artwork and not an emotion.
Topic modeling has been used to analyze large-scale book collections published before 1922 and therefore available in full-text form (Mimno & McCallum 2007). In this work I present a case study on the use of topic modeling in digitized corpora protected by copyright that we cannot access in their entirety, in this case books on Greco-Roman and Near-Eastern archeology that have been digitized by Google. The resulting resource, the Open Encyclopedia of Classical Sites, is based on a collection of 240-character search result snippets provided by Google. These short segments of text represent a small fraction of the overall corpus, but can nevertheless be used to build a representation of the contents of the books.
The construction of the corpus involved first selecting a subset of the entire books collection that appeared relevant to Greco-Roman and Near-Eastern archeology. I then defined a set of query terms related to specific archeological sites. These terms were then used to construct the corpus of search result snippets. In this way I was able to use a non-consumptive interface (the search engine) to create a usable sub-corpus without recreating large sections of the original books.
Preprocessing was a substantial challenge. I faced problems such as identifying language in highly multilingual text, recognizing improperly split words, and detecting multi-word terms. This process required access to words in their original sequence, and therefore could not be accomplished on unigram word count data.
Finally I trained a topic model on the corpus and integrated the resulting model with the Pleiades geographic database. This alignment between concepts and geography reveals many patterns. Some themes are geographically or culturally based, such as Egypt, Homeric Greece, or Southern Italy. Other themes cut across many regions, such as descriptions of fortifications or research on trade patterns.
The resulting resource, the Open Encyclopedia of Classical Sites, links geography to research literature in a way that has not previously been available. Users can browse the collection along three major axes. First, they can scan through a list of topics, which succinctly represent the major themes of the book collection, and the specific sites and volumes that refer to each theme. Second, they can select a particular site or geographic region and list the themes associated with that site. For example, the city of Pylos in Greece is the site of a major Mycenaean palace that contained many Linear B tablets, is associated with a character in the Homeric epics, and was the site of a battle in the Peloponnesian war. The topics associated with the site distinguish words related to Linear B tablets, Mycenaean palaces, characters in Homer, and Athens and Sparta. Finally, users can select a specific book and find the themes and sites contained in that volume.
This project provides a model both for what is possible given large digital book collections and for what is feasible given current copyright law. Realistically, we cannot expect to analyze the full text of books published after 1922. But we should also not be satisfied with search and simple keyword histograms. Short snippets provide sufficient lexical context to fix many OCR-related problems and support semantically enriched searching, browsing, and analysis.
Funding
This work was supported by a Google Digital Humanities Research grant.
References
Blei, D. M., A. Ng, and M. I. Jordan (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research 3: 993-1022.
Boyle, J. (2008). The Public Domain. New Haven: Yale UP.
Google, Inc. (2011). Amended Settlement Agreement. http://www.googlebooksettlement.com, accessed Mar 24, 2012.
Michel, J., Y. Shen, A. Aiden, A. Veres, M. Gray, J. Pickett, D. Hoiberg, D. Clancy, P. Norvig, J. Orwant, S. Pinker, M. Nowak, and E. Aiden. (2011). Quantitative analysis of culture using millions of digitized books. Science 331(6014): 176-82.
Mimno, D., and A. McCallum (2007). Organizing the OCA. In Proceedings of the Joint Conference on Digital Libraries. Vancouver, BC, June 2007.
Moretti, F. (2000). Conjectures on World Literature. New Left Review (Jan/Feb): 54-68.
Notes
1.Joint work by the author with Jason Baldridge, Katrin Erk, Taesun Moon, and Michael Speriosu. Aspects of this work were presented by Speriosu et al. (2010) and will appear in an article in an upcoming special issue of Texas Studies in Literature and Language.
2.Joint work by the author with Jordan Boyd-Graber and Thomas Clay Templeton. We have also presented results from this work at the 2011 Chicago Colloquium on Digital Humanities and Computer Science on experiments using casualty rates as the response variable.